Протокол затопления (flooding)
Каждый маршрутизатор отвечает за те и только те записи в базе данных состояния связей, которые описывают связи, исходящие от данного маршрутизатора. Это значит, что при образовании новой связи, изменении в состоянии связи или ее исчезновении (обрыве), маршрутизатор, ответственный за эту связь, должен соответственно изменить свою копию базы данных и немедленно известить все остальные маршрутизаторы OSPF-системы о произошедших изменениях, чтобы они также внесли исправления в свои копии базы данных.
Подпротокол OSPF, выполняющий эту задачу, называется протоколом затопления (Flooding protocol). При работе этого протокола пересылаются сообщения типа "Обновление состояния связей (Link State Update)" (см. также ), получение которых подтверждается сообщениями типа "Link State Acknowledgment" (см. также ).
Каждая запись о состоянии связей имеет свой номер (номер версии), который также хранится в базе данных. Каждая новая версия записи имеет больший номер. При рассылке сообщений об обновлении записи в базе данных номер записи также включается в сообщение для предотвращения попадания в базу данных устаревших версий.
Маршрутизатор, ответственный за запись об изменившейся связи, рассылает сообщение "Обновление состояния связи" по всем интерфейсам. Однако новые версии состояния одной и той же связи должны появляться не чаще, чем оговорено определенной константой.
Далее на всех маршрутизаторах OSPF-системы действует следующий алгоритм.
1. Получить сообщение. Найти соответствующую запись в базе данных. 2. Если запись не найдена, добавить ее в базу данных, передать сообщение по всем интерфейсам. 3. Если номер записи в базе данных меньше номера пришедшего сообщения, заменить запись в базе данных, передать сообщение по всем интерфейсам. 4. Если номер записи в базе данных больше номера пришедшего сообщения и эта запись не была недавно разослана, разослать содержимое записи из базы данных через тот интерфейс, откуда пришло сообщение. Понятие "недавно" определяется значением константы. 5. В случае равных номеров сообщение игнорировать.
Протокол OSPF устанавливает также такую характеристику записи в базе данных, как возраст. Возраст равен нулю при создании записи. При затоплении OSPF-системы сообщениями с данной записью каждый маршрутизатор, который ретранслирует сообщение, увеличивает возраст записи на определенную величину. Кроме этого, возраст увеличивается на единицу каждую секунду. Из-за разницы во времени пересылки, в количестве промежуточных маршрутизаторов и по другим причинам возраст одной и той же записи в базах данных на разных маршрутизаторах может несколько различаться, это нормальное явление.
При достижении возрастом максимального значения (60 минут), соответствующая запись расценивается маршрутизатором как просроченная и непригодная для вычисления маршрутов. Такая запись должна быть удалена из базы данных.
Поскольку базы данных на всех маршрутизаторах системы должны быть идентичны, просроченная запись должна быть удалена из всех копий базы данных на всех маршрутизаторах. Это делается с использованием протокола затопления: маршрутизатор затапливает систему сообщением с просроченной записью. Соответственно, в описанный выше алгоритм обработки сообщения вносятся дополнения, связанные с получением просроченного сообщения и удалением соответствующей записи из базы данных.
Чтобы записи в базе данных не устаревали, маршрутизаторы, ответственные за них, должны через каждые 30 минут затапливать систему сообщениями об обновлении записей, даже если состояние связей не изменилось. Содержимое записей в этих сообщениях неизменно, но номер версии больше, а возраст равен нулю.
Вышеописанные протоколы обеспечивают актуальность информации, содержащейся в базе данных состояния связей, оперативное реагирование на изменения в топологии системы сетей и синхронизацию копий базы данных на всех маршрутизаторах системы.
Для обеспечения надежности передачи данных реализован механизм подтверждения приема сообщений, также для всех сообщений вычисляется контрольная сумма.
В протоколе OSPF может быть применена аутентификация сообщений, например, защита их с помощью пароля.
(С)
Proxy ARP
ARP-ответ может отправляться не обязательно искомым узлом, вместо него это может сделать другой узел. Такой механизм называется proxy ARP.
Рассмотрим пример (рис. 2.6.1). Удаленный хост А подключается по коммутируемой линии к сети 194.84.124.0/24 через сервер доступа G. Сеть 194.84.124.0 на физическом уровне представляет собой Ethernet. Сервер G выдает хосту А IP-адрес 194.84.124.30, принадлежащий сети 194.84.124.0. Следовательно, любой узел этой сети, например, хост В, полагает, что может непосредственно отправить дейтаграмму хосту А, поскольку они находятся в одной IP-сети.
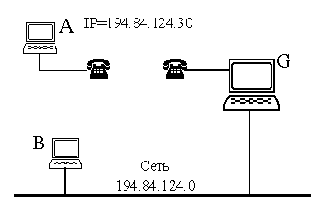
Рис. 2.6.1. Proxy ARP
IP-модуль хоста В вызывает ARP-модуль для определения физического адреса А. Однако вместо А (который, разумеется, откликнуться не может, потому что физически не подключен к сети Ethernet) откликается сервер G, который и возвращает свой Ethernet-адрес как физический адрес хоста А. Вслед за этим В отправляет, а G получает кадр, содержащий дейтаграмму для А, которую G отправляет адресату по коммутируемому каналу.
(С)
Работа протокола RIP
Для каждой записи в таблице маршрутов существует время жизни, контролируемое таймером. Если для любой конкретной сети, внесенной в таблицу маршрутов, в течение 180 с не получен вектор расстояний, подтверждающий или устанавливающий новое расстояние до данной сети, то сеть будет отмечена как недостижимая (расстояние равно бесконечности). Через определенное время модуль RIP производит "сборку мусора" - удаляет из таблицы маршрутов все сети, расстояние до которых бесконечно.
При получении сообщения типа "ответ" для каждого содержащегося в нем элемента вектора расстояний модуль RIP выполняет следующие действия:
проверяет корректность адреса сети и маски, указанных в сообщении;
проверяет, не превышает ли метрика (расстояние до сети) бесконечности;
некорректный элемент игнорируется;
если метрика меньше бесконечности, она увеличивается на 1;
производится поиск сети, указанной в рассматриваемом элементе вектора расстояний, в таблице маршрутов;
если запись о такой сети в таблице маршрутов отсутствует и метрика в полученном элементе вектора меньше бесконечности, сеть вносится в таблицу маршрутов с указанной метрикой; в поле "Следующий маршрутизатор" заносится адрес маршрутизатора, приславшего сообщение; запускается таймер для этой записи в таблице;
если искомая запись присутствует в таблице с метрикой больше, чем объявленная в полученном векторе, в таблицу вносятся новые метрика и, соответственно, адрес следующего маршрутизатора; таймер для этой записи перезапускается;
если искомая запись присутствует в таблице и отправителем полученного вектора был маршрутизатор, указанный в поле "Следующий маршрутизатор" этой записи, то таймер для этой записи перезапускается; более того, если при этом метрика в таблице отличается от метрики в полученном векторе расстояний, в таблицу вносится значение метрики из полученного вектора;
во всех прочих случаях рассматриваемый элемент вектора расстояний игнорируется.
Сообщения типа "ответ" рассылаются модулем RIP каждые 30 с по широковещательному или мультикастинговому (только RIP-2) адресу; рассылка "ответа" может происходить также вне графика, если маршрутная таблица была изменена (triggered response). Стандарт требует, чтобы triggered response рассылался не немедленно после изменения таблицы маршрутов, а через случайный интервал длительностью от 1 до 5 с. Эта мера позволяет несколько снизить нагрузку на сеть.
В каждую из сетей, подключенных к маршрутизатору, рассылается свой собственный вектор расстояний, построенный с учетом , сформулированного выше в п. 4.2.1. Там, где это возможно, адреса сетей агрегируются (обобщаются), то есть несколько подсетей с соседними адресами объединяются под одним, более общим адресом с соответствующим изменением маски.
В случае triggered response посылается информация только о тех сетях, записи о которых были изменены.
Информация о сетях с бесконечной метрикой посылается только в том случае, если она была недавно изменена.
При получении сообщения типа "запрос" с адресом 0.0.0.0 маршрутизатор рассылает в соответствующую сеть обычное сообщение типа ответ. При получении запроса с любым другим значением в поле (полях) "IP Address" посылается ответ, содержащий информацию только о сетях, которые указаны. Такой ответ посылается на адрес запросившего маршрутизатора (не широковещательно), при этом из п. 4.2.1 не учитывается.
Расщепление подтверждений
Пусть узел А, после установления соединения, находится в режиме медленного старта. Окно перегрузки cwnd равно одному полноразмерному сегменту, который и высылается в В (рис. 2.91). Однако В, вместо того, чтобы ответить одним подтверждением о получении всего сегмента (ACK SN=1001), высылает несколько подтверждений с возрастающими номерами ACK SN (например, 300, 600 и, наконец, 1001), как бы подтверждая получение сегмента по частям.
Отметим, что стандарт TCP при этом не нарушается, потому что в TCP подтверждается получение октетов, а не сегментов. Однако алгоритм медленного старта неявно подразумевает, что получатель посылает не более одного подтверждения при получении каждого очередного сегмента, и, как следствие, окно cwnd увеличивается на один полноразмерный сегмент с приходом каждого подтверждения, независимо от того, получение какого числа октетов оно подтверждает.
В итоге при нормальном поведении узла В отправитель на следующем шаге увеличил бы окно cwnd только на 1 сегмент и отправил бы в В два следующих полноразмерных сегмента (SN=1001 и 2001). Но узел В, выслав три подтверждения вместо одного, вынудил узел А увеличить значение cwnd до 4 и отправить 4 сегмента вместо двух.
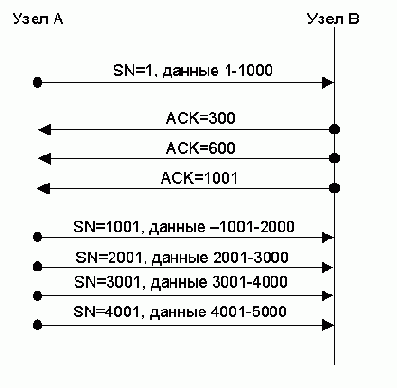
Рис. 9.14. Расщепление подтверждений
В общем случае, если полноразмерный сегмент содержит N октетов, то узел В может отправить M <= N подтверждений. Простые арифметические подсчеты показывают, что тогда на i-м шаге (то есть через время RTT*i, где RTT — время обращения) узел А будет отправлять не N*2i октетов, как это было бы при нормальном поведении получателя, а порядка N*Mi октетов, если, конечно, узел В позаботится об объявлении подобающего размера окна получателя. Типичный размер поля данных сегмента — 1460 октетов. Наиболее агрессивное поведение получателя (1460 подтверждений на каждый сегмент) теоретически приведет к тому, что уже после третьего шага узел В может получить 2,9 Гбайт данных. Разумеется, скорость не может расти бесконечно — она будет ограничена возможностями сети и узла-отправителя.
Разделение каналов
Протокол TCP обеспечивает работу одновременно нескольких соединений. Каждый прикладной процесс идентифицируется номером порта. Заголовок TCP-сегмента содержит номера портов процесса-отправителя и процесса-получателя. При получении сегмента модуль TCP анализирует номер порта получателя и отправляет данные соответствующему прикладному процессу.
Все распространенные сервисы Интернет имеют стандартизованные номера портов. Например, номер порта сервера электронной почты - 25, сервера FTP - 21. Список стандартных номеров портов можно найти в файле /etc/services (Unix).
Совокупность IP-адреса и номера порта называется сокетом. Сокет уникально идентифицирует прикладной процесс в Интернет. Например, сокет сервера электронной почты на хосте 194.84.124.4 обозначается как 194.84.124.4.25; часто номер порта отделяется двоеточием.
Разграничение хостов и маршрутизаторов
Выше мы разбирали систему сетей, состоящую только из маршрутизаторов, соединенных двухточечными линиями связи. В этой системе отсутствовали хосты.
Предположим, что к маршрутизатору ?
подключена сеть N1 из некоторого количества хостов H1-Hk. Следуя разобранной выше модели, каждый хост должен быть также вершиной графа OSPF-системы, хотя сам и не строит базу данных и не производит вычисления маршрутов. Тем не менее, информация о связях маршрутизатора ?
с каждым из хостов сети N1 и о метриках этих связей должна быть внесена в базу данных, чтобы все остальные маршрутизаторы системы могли построить маршруты от себя до этих хостов.
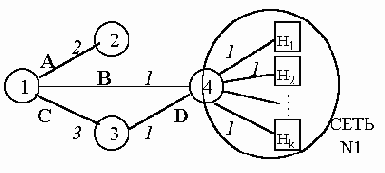
Рис. 5.1.3. OSPF-система с маршрутизаторами и хостами
Очевидно, что такая процедура неэффективна. Вместо информации о связях с каждым хостом в базу данных вносится информация о связи с сетью, то есть сама IP-сеть становится вершиной графа системы, соединенной с маршрутизатором ?
с помощью некоторой связи P.
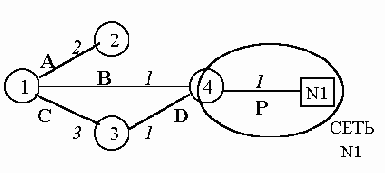
Рис. 5.1.4. OSPF-система с маршрутизаторами и тупиковой сетью
Подчеркнем, что в данном случае сеть, точнее ее адрес, используется как обобщающий идентификатор группы хостов, находящихся в одной IP-сети, к которой маршрутизатор ?
непосредственно подключен. Вершина N1 называется тупиковой сетью (stub network); все узлы сети, обозначаемые этой вершиной, являются хостами, у которых установлен маршрут по умолчанию, направленный на маршрутизатор ?.
Протокол OSPF производит разграничение хостов и маршрутизаторов. Если к IP-сети N1 подключен еще и один из интерфейсов маршрутизатора ?
, то связь между ?
и ?
будет установлена отдельно, как если бы они были соединены двухточечной линией связи (при этом у маршрутизатора ?
также будет связь с тупиковой сетью N1).
При подключении тупиковой сети N1 в базе данных состояния связей появится запись:
| Отaдо | Связь | Метрика |
| ?aN1 | P | 1 |
Связей, направленных из вершины N1, в базе данных не будет, потому что вершина N1 не является маршрутизатором. Построение маршрутов до вершины N1 (то есть фактически сразу до всех хоcтов сети N1) будет произведено каждым маршрутизатором обычным способом по алгоритму SPF.
Разрыв магистрали
Рассмотрим случай, когда магистраль в результате аварии или изначально оказалась разделенной на две части, связь между которыми может быть установлена только через сети, принадлежащие одной из периферийных областей. На примере нашей автономной системы предположим, что сети B и H перестали функционировать или отсутствуют. Следовательно, связь магистральных сетей А и С, с одной стороны, и К и G, с другой стороны, возможна только через сети E, I, L, не принадлежащие магистрали.
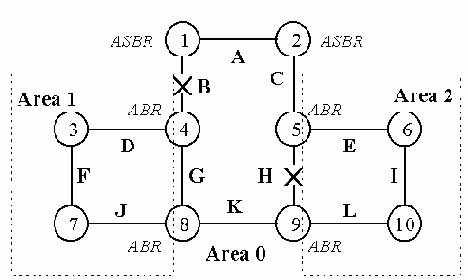
Рис. 5.4.2. Разрыв магистрали
В этом случае между маршрутизаторами ?
и ?
, принадлежащими магистрали, должна быть сконфигурирована виртуальная связь, которая вносится в базу данных состояния связей магистрали с метрикой, равной метрике реального "обходного" пути через область 2, эта метрика в нашем случае равна 3. Таким образом, при расчете маршрутов маршрутизаторы магистрали считают, что ?
и ?
соединены непосредственно друг с другом и связность магистрали восстанавливается.
На каждом из маршрутизаторов ?
и ?
при конфигурировании виртуальной связи указывается его партнер по виртуальной связи и область, через которую проходит реальный маршрут виртуальной связи, такая область называется транзитной. Виртуальная связь считается связью типа "точка-точка", следовательно, маршрутизаторы ?
и ?
устанавливают между собой отношения смежности через эту связь.
Разумеется, при необходимости использовать маршрут, лежащий через виртуальную связь, узел ?
должен вместо этого отправлять дейтаграммы узлу ?
, который, руководствуясь своей маршрутной таблицей, направит их дальше через область 2, в конце концов они попадут к маршрутизатору ?
и будут отправлены по назначению. Соответствующие действия при необходимости использовать виртуальную связь предпримет и узел ?
.
В случае отсутствия виртуальной связи коннективность между сетями А и С, с одной стороны, и сетями G, K и областью 1, с другой стороны, будет отсутствовать, несмотря на существование физического маршрута через область 2. Это связано, например, с тем, что маршрутизатор ?
подключен к магистрали, следовательно, маршруты до сетей А и С, принадлежащих магистрали, он должен рассчитывать по базе данных магистрали. Однако граф магистрали больше не является связным и сети А и С недостижимы. Несмотря на то, что ?
объявляет данные о достижимости сетей А и С в области 2, эти данные используются только внутренними маршрутизаторами области.
Реализация BGP
Пара BGP-соседей устанавливает между собой соединение по протоколу TCP, порт 179. Соседи, принадлежащие разным АС, должны быть доступны друг другу непосредственно; для соседей из одной АС такого ограничения нет, поскольку протокол внутренней маршрутизации обеспечит наличие всех необходимых маршрутов между узлами одной автономной системы.
Поток информации, которым обмениваются BGP-соседи по протоколу TCP, состоит из последовательности BGP-сообщений. Максимальная длина сообщения 4096 октетов, минимальная– 19. Имеется 4 типа сообщений.
Реализация протокола RIP
Существуют две версии протокола RIP: RIP-1 и RIP-2. Версия 2 имеет некоторые усовершенствования, как то: возможность маршрутизации сетей по модели CIDR (кроме адреса сети передается и маска), поддержка мультикастинга, возможность использования аутентификации RIP-сообщений и др.
RPF
Метод RPF (Reverse Path Forwarding) состоит в следующем.
Маршрутизатор получил через интерфейс I групповую дейтаграмму от источника S. Если через I лежит кратчайший маршрут от данного маршрутизатора до узла S, то ретранслировать дейтаграмму через все интерфейсы кроме того, с которого она получена. Иначе дейтаграмму игнорировать.
Например (рис. 8.3.2, а) маршрутизатор В проигнорирует дейтаграмму, полученную от узла С, но примет дейтаграмму от узла Е и ретранслирует ее через все остальные интерфейсы.
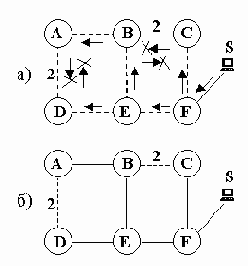
Рис. 8.3.2. Метод RPF
а) рассылка дейтаграмм; б) сформированное дерево рассылки
S – источник, A-F – маршрутизаторы;
метрики всех сетей, кроме явно указанных, равны 1
В результате каждый маршрутизатор принимает для ретрансляции только те групповые дейтаграммы, которые следуют от источника к маршрутизатору по кратчайшему пути. Иными словами, дейтаграммы распространяются от источника ко всем маршрутизаторам системы по оптимальному остовому дереву с корнем в источнике (рис. 8.3.2, б). Для каждого источника такое дерево возникает автоматически по мере продвижения дейтаграммы.
Однако поскольку ретрансляция групповой дейтаграммы производится маршрутизатором через все интерфейсы, кроме входного, некоторые экземпляры дейтаграммы являются лишними и засоряют сеть. Речь идет о тех дейтаграммах, которые будут отброшены соседними маршрутизаторами на основании того, что они прибыли с "неоптимальных" интерфейсов, то есть распространялись не по ветвям дерева (например, дейтаграмма, посланная узлом С к узлу В на рис. 8.3.2, а). Избежать ретрансляции дейтаграммы через связи, не принадлежащие дереву, можно с помощью следующей модификации алгоритма: "Полученная групповая дейтаграмма предается только в те сети, где находятся маршрутизаторы, кратчайший маршрут к которым от узла S проходит через данный маршрутизатор." Следуя этому правилу, узел С не отправит дейтаграмму в В, поскольку кратчайший путь от источника до узла В проходит не через С.
Важно отметить, что для реализации метода RPF необходимо иметь доступ к таблице маршрутов. Более того, для реализации модифицированного алгоритма требуется доступ к внутренним данным протокола внутренней маршрутизации (например, к базе данных состояния связей OSPF) – иначе нельзя сделать вывод о маршрутах, используемых другими узлами системы (источниками групповых дейтаграмм).
Следующая модификация RPF призвана учесть наличие или отсутствие получателей групповой дейтаграммы в сетях системы с тем, чтобы дейтаграммы рассылались только в те сети, где есть члены данной группы. Применяемый для этого метод называется prunes – усечение (от английского prune – "обрезать ветви дерева").
Первая групповая дейтаграмма распространяется обычным образом по алгоритму RPF и достигает всех маршрутизаторов системы. Если к какому-то "конечному" маршрутизатору не присоединены члены данной группы (это устанавливается с помощью протокола IGMP), он посылает через тот интерфейс, откуда получил групповую дейтаграмму, специальное сообщение Prune (по адресу данной группы). Это сообщение, принятое маршрутизатором, находящемся в вышестоящем узле дерева, означает "не посылать больше через этот интерфейс дейтаграммы от данного источника для данной группы". Вышестоящий маршрутизатор помечает этот интерфейс как pruned (усеченный) на определенный срок. По истечении этого срока процесс повторяется сначала. Однако имеется сообщение Graft (от английского "прививать растение"), позволяющее быстро подсоединиться к существующему дереву (то есть отменить ранее посланное Prune), не дожидаясь очередной рассылки "пробной" дейтаграммы.
Если Prune получено от всех нижележащих маршрутизаторов, маршрутизатор отправляет Prune еще более вышестоящему маршрутизатору– таким образом можно усекать целые поддеревья.
Метод RPF (с усечением) обладает следующими чрезвычайно существенными достоинствами:
групповые дейтаграммы от каждого источника рассылаются по оптимальным путям – и эти пути определяются динамически в момент рассылки;
при этом учитывается членство в группах – дейтаграммы в сети, где нет получателей, не рассылаются;
групповой трафик распределяется по различными сегментам системы сетей, а не концентрируется в определенном подмножестве связей.
Недостатки рассматриваемого метода:
Каждый маршрутизатор должен хранить таблицу, в которой отслеживается получение сообщений Prune, и производить поиск в ней при получении каждой дейтаграммы. Размер этой таблицы равен произведению числа интерфейсов, числа групп и числа источников, дейтаграммы от которых проходили через маршрутизатор. (Отметим, что источники нужно запоминать тоже, так как для каждого источника создается свое дерево рассылки.) Безусловно, эта таблица не так велика, как при использовании веерной рассылки, но при интенсивном групповом трафике ее поддержка может отнять существенные ресурсы.
Первая групповая дейтаграмма и, периодически, последующие "пробные" распространяются по всей системе сетей. При этом если в группе мало членов, а система велика (например, Интернет), возникает избыточный трафик, состоящий как из ретранслируемых экземпляров дейтаграммы, так и из потока Prune-сообщений, которые к тому же требуется обработать и внести в таблицу.
Необходимость наличия интерфейса к структурам данных модуля маршрутизации (или необходимость создания "сопровождающего" протокола маршрутизации) увеличивает сложность реализации RPF.
Несмотря на описанные недостатки, именно метод RPF лежит в основе многих протоколов групповой маршрутизации.
Сбой системы
DoS-атаки этой группы не связаны с какими-либо проблемами протоколов стека TCP/IP, а используют ошибки в их программной реализации. Эти ошибки сравнительно просто исправить. Мы дадим краткий обзор наиболее известных атак, имея в виду, что в скором времени они, видимо, будут представлять лишь исторический интерес. С другой стороны нет никаких гарантий того, что не будут обнаружены новые ошибки. Все описываемые ниже атаки приводят к общему сбою уязвимой системы. Для защиты от них необходимо использовать последние версии операционных систем и следить за обновлениями к ним.
Ping of death
Атака состоит в посылке на атакуемый узел фрагментированной датаграммы, размер которой после сборки превысит 65 535 октетов. Напомним, что длина поля Fragment Offset заголовка IP-датаграммы — 13 битов (то есть, максимальное значение равно 8192), а измеряются смещения фрагментов в восьмерках октетов. Если последний фрагмент сконструированной злоумышленником датаграммы имеет, например, смещение Fragment Offset=8190, а длину — 100, то его последний октет находится в собираемой датаграмме на позиции 8190*8+100=65620 (плюс как минимум 20 октетов IP-заголовка), что превышает максимальный разрешенный размер датаграммы.
Teardrop
Атака использует ошибку, возникающую при подсчете длины фрагмента во время сборки датаграммы. Предположим, фрагмент А имеет смещение 40 (Fragment Offset=5) и длину 120, а фрагмент В — смещение 80 и длину 160, то есть фрагменты накладываются, что, в общем-то, разрешено. Модуль IP вычисляет длину той части фрагмента В, которая не накладывается на А: (80+160) – (40+120)=80, и копирует последние 80 октетов фрагмента В в буфер сборки. Предположим, злоумышленник сконструировал фрагмент В так, что тот имеет смещение 80, а длину 72. Вычисление длины перекрытия дает отрицательный результат: (80+72) – (40+120)= –8, что с учетом представления отрицательных чисел в машинной арифметике интерпретируется как 65528, и программа начинает записывать 65 528 байтов в буфер сборки, переполняя его и затирая соседнюю область памяти.
Land
Атака состоит в посылке на атакуемый узел SYN-сегмента TCP, у которого IP-адрес и порт отправителя совпадают с адресом и портом получателя.
Nuke
Атака состоит в посылке на атакуемый TCP-порт срочных данных (задействовано поле Urgent Pointer). Атака поражала через порт 139 Windows-системы, в которых в прикладном процессе не была предусмотрена возможность приема срочных данных, что приводило к краху системы.
Счет до бесконечности
Рассмотрим следующую систему сетей:
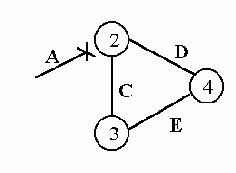
Рис. 4.2.2. Пример RIP-системы (иллюстрация счета до бесконечности)
Первоначально сеть А была подсоединена к узлу ?
, но в какой-то момент времени произошла авария и сеть А оказалась изолированной.
До момента аварии маршрутизаторы имели следующие записи относительно сети А:
Узел ?
А=1a
?
Узел ?
А=2a
?
Узел ?
А=2a
?
Немедленно после аварии запись в таблице маршрутов узла А изменяется на А=16a
?
, это говорит о том, что сеть А недостижима, а точнее, что сеть А через узел ?
недостижима.
Вектор расстояний, рассылаемый из ?
, с элементом A=16 достигает узла ?
, но по какой-то причине задерживается на пути в ?
. Согласно дополнениям к алгоритму рассылки векторов расстояний, приведенным в предыдущем пункте, узел ?
вносит в свою таблицу запись А=16a
?
и рассылает вектор с элементом А=16.
В этот момент узел ?
, до которого сообщение от узла ?
о недостижимости сети А еще не дошло, рассылает в сети Е свой вектор с элементом А=2. Узел ?
получает этот вектор, прибавляет к расстоянию 1 и замечает, что оно меньше записанного в таблице (бесконечность), следовательно, в таблице маршрутов узла ?
появляется запись А=3a
?
. Вектор расстояний с элементом А=3 рассылается узлом ?
в сети С и достигает узла ?
.
Узел ?
, руководствуясь теми же соображениями, что и узел ?
ранее, модифицирует свою таблицу: А=4a
?
.
Примерно в это время узел ?
получает наконец-то вектор А=16, отправленный после аварии узлом ?
, но вслед за этим из узла ?
приходит вектор А=4, который узел ?
рассылает в сети D. Поскольку ?
отправляет дейтаграммы в сеть А через ?
, он обязан реагировать на любые объявления узлом ?
расстояния до сети А. Поэтому в таблице узла ?
появляется А=5a
?
.
Соответствующий вектор от узла ?
с элементом А=5 достигает по сети Е узел ?
, в таблице маршрутов которого указано, что дейтаграммы в сеть А он отправляет через ?
. Следовательно, узел ?
обязан реагировать на любые объявления узлом ?
расстояния до сети А. Поэтому в таблице узла ?
появляется А=6a
?
.
Вектор от узла ?
с элементом А=6 достигает по сети С узел ?
, в таблице маршрутов которого указано, что дейтаграммы в сеть А он отправляет через ?
. Следовательно, узел ?
обязан реагировать на любые объявления узлом ?
расстояния до сети А. Поэтому в таблице узла ?
появляется А=7a
?
.
Далее все повторяется по кругу до тех пор, пока расстояние до А не станет равным бесконечности в таблицах всех трех маршрутизаторов. Несмотря на это в течение "счета до бесконечности" сеть А считается достижимой, поскольку расстояние до нее считается конечным, и все дейтаграммы, адресованные в сеть А, отправляются маршрутизаторами согласно их таблицам, то есть по кругу, что нельзя признать разумной и корректной маршрутизацией.
Существуют и более сложные ситуации, когда возникает необходимость "счета до бесконечности". Чтобы уменьшить отрицательный эффект этого явления, значение бесконечности не должно быть велико. В протоколе RIP оно равно 16, что в свою очередь ограничивает размер RIP-системы.
Семиуровневая модель OSI
Модель OSI (Open System Interconnect Reference Model, Эталонная модель взаимодействия открытых систем) представляет собой универсальный стандарт на взаимодействие двух систем (компьютеров) через вычислительную сеть.
Эта модель описывает функции семи иерархических уровней и интерфейсы взаимодействия между уровнями. Каждый уровень определяется сервисом, который он предоставляет вышестоящему уровню, и протоколом- набором правил и форматов данных для взаимодействия между собой объектов одного уровня, работающих на разных компьютерах.
Идея состоит в том, что вся сложная процедура сетевого взаимодействия может быть разбита на некоторое количество примитивов, последовательно выполняющихся объектами, соотнесенными с уровнями модели. Модель построена так, что объекты одного уровня двух взаимодействующих компьютеров сообщаются непосредственно друг с другом с помощью соответствующих протоколов, не зная, какие уровни лежат под ними и какие функции они выполняют. Задача объектов - предоставить через стандартизованный интерфейс определенный сервис вышестоящему уровню, воспользовавшись, если нужно, сервисом, который предоставляет данному объекту нижележащий уровень.
Например, некий процесс отправляет данные через сеть процессу, находящемуся на другом компьютере. Через стандартизованный интерфейс процесс-отправитель передает данные нижнему уровню, который предоставляет процессу сервис по пересылке данных, а процесс-получатель через такой же стандартизованный интерфейс получает эти данные от нижнего уровня. При этом ни один из процессов не знает и не имеет необходимости знать, как именно осуществляет передачу данных протокол нижнего уровня, сколько еще уровней находится под ним, какова физическая среда передачи данных и каким путем они движутся.
Эти процессы, с другой стороны, могут находиться не на самом верхнем уровне модели. Предположим, что они через стандартный интерфейс взаимодействуют с приложениями вышестоящего уровня и их задача (предоставляемый сервис) - преобразование данных, а именно фрагментация и сборка больших блоков данных, которые вышестоящие приложения отправляют друг другу. При этом сущность этих данных и их интерпретация для рассматриваемых процессов совершенно не важны.
Возможна также взаимозаменяемость объектов одного уровня (например, при изменении способа реализации сервиса) таким образом, что объект вышестоящего уровня не заметит подмены.
Вернемся к примеру: приложения не знают о том, что их данные преобразуются именно путем фрагментации/сборки, им достаточно знать то, что нижний уровень предоставляет им некий “правильный” сервис преобразования данных. Если же для какой-то другой сети понадобится не фрагментация/сборка пакетов, а, скажем, перестановка местами четных и нечетных бит, то процессы рассматриваемого уровня будут заменены, но приложения ничего не заметят, так как их интерфейсы с нижележащим уровнем стандартизованы, а конкретные действия нижележащих уровней скрыты от них.
Объекты, выполняющие функции уровней, могут быть реализованы в программном, программно-аппаратном или аппаратном виде. Как правило, чем ниже уровень, тем больше доля аппаратной части в его реализации.
Организация сетевого взаимодействия компьютеров, построенного на основе иерархических уровней, как описано выше, часто называется протокольным стеком.
Сети множественного доступа
Протокол OSPF особым образом выделяет сети множественного доступа, то есть сети, где каждый узел может непосредственно связаться с каждым. Такие сети могут также поддерживать широковещательную передачу и мультикастинг (broadcast networks, например, Ethernet, FDDI) или не поддерживать таковой (non-broadcast multi-access networks, NBMA, например, Х.25, Frame Relay, ATM).
Рассмотрим сначала случай широковещательной сети, к которой подключено несколько маршрутизаторов. Следуя модели работы протоколов состояния связей, связь каждой пары маршрутизаторов должна рассматриваться как связь типа "точка-точка", что значит: каждый маршрутизатор должен установить смежность с каждым, то есть всего N(N-1)/2 отношений смежности, по которым происходит обмен всеми типами сообщений, описанных в . Каждый маршрутизатор будет вносить в базу данных N-1 записей о связях с другими маршрутизаторами плюс одна связь с вершиной типа "тупиковая сеть" (то есть с хостами, которые тоже могут находиться в этой IP-сети), всего в базе данных будет N2 записей, касающихся рассматриваемой сети.
Сканирование сети
Сканирование сети имеет своей целью выявление подключенных к сети компьютеров и определение работающих на них сетевых сервисов (открытых портов TCP или UDP). Первая задача выполняется посылкой ICMP-сообщений Echo с помощью программы ping с последовательным перебором адресов узлов в сети. Стоит попробовать отправить Echo-сообщение по широковещательному адресу — на него ответят все компьютеры, поддерживающие обработку таких сообщений.
Администратор сети может обнаружить попытки сканирования путем анализа трафика в сети и отслеживания Echo-сообщений, за короткий промежуток времени посылаемых последовательно по всем адресам сети. Для большей скрытности злоумышленник может существенно растянуть процесс во времени («медленное сканирование») — это же касается и сканирования портов TCP/UDP. Также злоумышленник может применить «обратное сканирование» (inverse mapping): в этом случае на тестируемые адреса посылаются не сообщения ICMP Echo, а другие сообщения, например RST-сегменты TCP, ответы на несуществующие DNS-запросы и т. п. Если тестируемый узел не существует (выключен), злоумышленник получит в ответ ICMP-сообщение Destination Unreachable: Host Unreachable.
Следовательно, если сообщение не было получено, то соответствующий узел подключен к сети и работает.
Программа traceroute поможет в определении топологии сети и обнаружении маршрутизаторов.
Для определения того, какие UDP- или TCP-приложения запущены на обнаруженных компьютерах, используются программы-сканеры, например, программа . Поскольку номера портов всех основных сервисов Интернета стандартизованы, то, определив, например, что порт 25/TCP открыт, можно сделать вывод о том, что данный хост является сервером электронной почты, и т. д. Полученную информацию злоумышленник может использовать для развертывания атаки на уровне приложения.
Сканирование TCP-портов хоста производится несколькими способами. Наиболее простой способ — установление TCP-соединения с тестируемым портом с помощью функции connect. Если соединение удалось установить, значит, порт открыт и к нему подсоединено серверное приложение. Достоинством этого способа является возможность выполнения сканирования любым пользователем, и даже без специального программного обеспечения: стандартная программа telnet позволяет указать произвольный номер порта для установления соединения. Существенный недостаток — возможность отслеживания и регистрации такого сканирования: при анализе системного журнала сканируемого хоста будут обнаружены многочисленные открытые и сразу же прерванные соединения, в результате чего могут быть приняты меры по повышению уровня безопасности.
Сканирование в режиме половинного открытия (half- open scanning) не имеет описанного недостатка, но требует от злоумышленника возможности формировать одиночные TCP-сегменты в обход стандартного модуля TCP (или, при использовании уже написанных программ, как минимум — прав суперпользователя). В этом режиме злоумышленник направляет на сканируемый порт SYN-сегмент и ожидает ответа. Получение ответного сегмента с битами SYN и ACK означает, что порт открыт; получение сегмента с битом RST означает, что порт закрыт. Получив SYN+ACK, злоумышленник немедленно отправляет на обнаруженный порт сегмент с битом RST, таким образом ликвидируя попытку соединения. Так как соединение так и не было открыто (ACK от злоумышленника не был получен), то зарегистрировать такое сканирование гораздо сложнее.
Третий способ — сканирование с помощью FIN-сегментов. В этом случае на сканируемый порт посылается сегмент с установленным битом FIN. Хост должен ответить RST-сегментом, если FIN-сегмент адресован закрытому порту. FIN-сегменты, направленные на порт, находящийся в состоянии LISTEN, многими реализациями TCP/IP игнорируются (стандарт требует в состоянии LISTEN посылать RST-сегменты в ответ на сегменты, имеющие неприемлемый ACK SN; про сегменты, имеющие только флаг FIN, ничего не говорится). Таким образом, отсутствие отклика говорит о том, что порт открыт. Варианты этого способа сканирования — посылка сегментов с флагами FIN, PSH, URG («Xmas scan») или вообще без всяких флагов («Null scan»).
Конечно, сканирование SYN-сегментами дает более надежные результаты, однако, к счастью, многие брандмауэры могут не пропускать SYN-сегменты без флага ACK из Интернета во внутреннюю сеть1 (так, запрещаются соединения хостов Интернета с внутренними хостами, инициируемые из Интернета, но разрешаются соединения, инициируемые изнутри).
1 О способе проникновения SYN-сегментов через брандмауэр с помощью фрагментации дейтаграмм см. п. .
Программа может зарегистрировать попытки сканирования в различных режимах.
Для определения открытых портов UDP злоумышленник может отправить на тестируемый порт UDP-сообщение. Получение в ответ ICMP-сообщения Port Unreachable (тип 3, код 3) говорит о том, что порт закрыт.
Программа-сканер может также определить операционную систему сканируемого узла по тому, как узел реагирует на специальным образом сконструированные, нестандартные пакеты: например, TCP-сегменты с бессмысленными сочетаниями флагов или ICMP-сообщения некоторых типов, и по другим признакам.
В марте 2001 г. в списке рассылки шла оживленная дискуссия об опции TCP Timestamp (Временной штамп) []. У многих систем часы модуля TCP, чьи показания помещаются в опцию Timestamp, связаны с системными часами, что позволяет по значению опции определить uptime — время, прошедшее с момента загрузки компьютера. Эта информация может представлять потенциальную угрозу для безопасности компьютера в следующих аспектах.
Некоторые реализации могут использовать uptime для инициализации генератора псевдослучайных чисел, который используется различными приложениями для создания серийных номеров, имен временных файлов и т. п., а также для назначения номеров ISN для TCP-соединений (о роли ISN в обеспечении безопасности см. п. ). Зная uptime и имея аналогичный генератор, злоумышленник может предсказать результаты его работы. Зная тип системы и время последней перезагрузки, можно сделать вывод, что заплаты (patches), касающиеся безопасности и вышедшие позже момента загрузки, в системе не установлены (если их установка требует перезагрузки). Наблюдая за системой продолжительное время, можно составить график ее регулярных перезагрузок и произвести имперсонацию хоста (п. ) в тот момент, когда он перегружается и не способен работать с сетью.
Однако возможность выполнения реальных атак с использованием значения uptime пока остается под вопросом.
В заключение отметим, что для определения адресов работающих в сети компьютеров и запущенных на них UDP- или TCP-сервисов злоумышленник, непосредственно подключенный к сегменту сети, может использовать простое прослушивание. Такая форма сканирования сети является более скрытной, чем рассылка тестирующих датаграмм.
9.1.3. Генерация пакетов
Генерация датаграмм или кадров произвольного формата и содержания производится не менее просто, чем прослушивание сети Ethernet. Библиотека обеспечит программиста всем необходимым для решения этой задачи. Библиотека предоставляет инструментарий для обратного действия — извлечения пакетов из сети и их анализа.
На многочисленных сайтах Интернета злоумышленник может найти уже готовые программы, генерирующие пакеты целенаправленно для выполнения какой-либо атаки или сканирования сети (например, программа nmap, упомянутая выше). Применение таких программ часто не требует от злоумышленника ни квалификации программиста, ни понимания принципов работы сети, что делает многие из описанных атак, особенно атаки типа «отказ в обслуживании», широко доступными для исполнения.
Сообщение Hello

Значения полей:
Network Mask (4 октета) - маска IP-сети, в которой находится интерфейс маршрутизатора, отправившего сообщение.
Hello Interval (2 октета) - период посылки Hello-сообщений, в секундах.
Options (1 октет) - определено значение нескольких бит:
DC
EA
N/P
MC
E
T
БитТ
установлен a
поддерживается маршрутизация по типу сервиса (этот бит исключен из последней версии стандарта OSPF, но может поддерживаться для совместимости с предыдущими версиями).
Бит Е
установлен a
маршрутизатор может принимать и объявлять внешние маршруты через данный интерфейс, сброшен a
данный интерфейс маршрутизатора принадлежит тупиковой области.
Бит MC
установлен a
маршрутизатор поддерживает маршрутизацию мультикастинговых дейтаграмм (RFC 1584, в этой части пособия не обсуждается).
Бит N/P
установлен a
данный интерфейс маршрутизатора принадлежит не совсем тупиковой области (NSSA).
Бит EA
установлен a
маршрутизатор может получать и ретранслировать объявления о "внешних атрибутах" (к настоящему моменту описание опции не разработано).
Бит DC
установлен a
маршрутизатор поддерживает работу с соединениями, устанавливаемыми по требованию (demand circuits, RFC 1793) - это, например, означает, что записи о связях, устанавливаемых по требованию, не устаревают.
Поле "Options" используется для согласования возможностей маршрутизаторов-соседей (маршрутизатор может прервать соседские отношения, если какие-то опции соседа его не устраивают) и для определения того, какую информацию о состоянии связей не нужно посылать маршрутизатору-соседу, потому что он все равно не сможет ее обработать.
Priority (1 октет) - приоритет маршрутизатора; устанавливается администратором, используется при выборах выделенного маршрутизатора; маршрутизатор с нулевым приоритетом никогда не будет избран.
Dead Interval (4 октета) - время в секундах, по истечении которого маршрутизатор-сосед, не посылающий сообщения Hello, считается отключенным.
Designated Router (DR) (4 октета) - идентификатор выделенного маршрутизатора с точки зрения маршрутизатора, посылающего сообщение (0, если выделенный маршрутизатор еще не выбран).
Backup Designated Router (BDR) (4 октета) - идентификтор запасного выделенного маршрутизатора с точки зрения маршрутизатора, посылающего сообщение (0, если запасной выделенный маршрутизатор еще не выбран).
Neighbor,..., Neighbor - список идентификаторов соседей, от которых получены Hello-сообщения за последние Dead Interval секунд; число полей "Neighbor" определяется из общей длины сообщения, указанной в OSPF-заголовке. Длина одного поля — 4 октета.
После того, как пара маршрутизаторов начинает обмениваться Hello-сообщениями с каким-то соседом, этот процесс проходит через несколько стадий:
DOWN - сосед не обнаружен или отключился;
INIT - послано Hello-сообщение или получено от маршрутизатора, еще не зачисленного в список соседей;
2-WAY (двусторонняя связь) - получено Hello-сообщение, в котором данный маршрутизатор-получатель перечислен в списке соседей, а отправитель этого сообщения также зачислен в список соседей данного маршрутизатора;
WAIT - ожидание в течение Dead Interval секунд для обнаружения всех соседей; в это время маршрутизатор передает Hello-сообщения, но не участвует в выборах выделенного маршрутизатора и в синхронизировании баз данных;
EXSTART - установление ролей главный/подчиненный и инициализация структур данных для обмена описаниями баз данных (протокол обмена);
EXCHANGE - обмен описаниями баз данных (протокол обмена);
LOADING - синхронизация баз данных, пересылка сообщений-запросов о состояниях связей и ответов на них (протокол обмена);
FULL - базы данных синхронизированы.
Каждый маршрутизатор самостоятельно производит выборы выделенного и запасного выделенного маршрутизаторов на основании имеющихся у него данных о соседях и о том, кого каждый из соседей назначил на эту роль. Фактически процесс выборов происходит постоянно, после получения каждого Hello-сообщения, но алгоритм гарантирует, что при стабильном состоянии сети всеми маршрутизаторами будут выбираться одни и те же DR и BDR.
Каждый маршрутизатор может объявить себя либо выделенным, либо запасным, поместив свой идентификатор в соответствующее поле своих Hello-сообщений. Иначе он может поместить туда адреса других маршрутизаторов, если он считает их занимающими соответствующие роли. Если маршрутизатор не определился с выбором DR и (или) BDR (например, после включения), он заполняет соответствующие поля нулями.
Выбор проводится только среди соседей, с которыми установлена двусторонняя связь и приоритет которых не равен нулю; в этот список маршрутизатор включает и себя, если его приоритет не нулевой.
Итак, после получения очередного Hello-сообщения маршрутизатор приступает к выбору DR и BDR. Он помнит мнения своих соседей по поводу того, кто является DR и BDR, которые он узнал из получаемых Hello-сообщений, а также свой собственный предыдущий выбор.
Сначала выбирается BDR, на эту должность назначается маршрутизатор с наивысшим приоритетом из всех, объявивших себя в качестве BDR, при этом маршрутизаторы, объявившие себя в качестве DR, не рассматриваются. Если никто не объявил себя в качестве BDR, выбирается маршрутизатор с высшим приоритетом из тех, кто не объявил себя в качестве DR. В случае равных приоритетов выбирается маршрутизатор с большим идентификатором.
На должность DR выбирается маршрутизатор с наивысшим приоритетом из всех, объявивших себя в качестве DR. В случае равных приоритетов выбирается маршрутизатор с большим идентификатором.
Если никто не предложил себя в качестве DR, в поле "Designated Router" заносится идентификатор BDR.
Если маршрутизатор только что выбрал себя на роль DR или BDR или только что потерял статус DR или BDR, шаги 1-3 повторяются. Термин "только что" означает "в результате выполнения непосредственно предшествующих шагов 1-3, а не предыдущих итераций алгоритма".
После выбора DR и BDR маршрутизатор сообщает их идентификаторы в своих Hello-сообщениях. Если в результате процедуры выбора DR или BDR изменились по сравнению с предыдущим выбором данного маршрутизатора, он устанавливает необходимые отношения смежности, если они еще не были установлены, и разрывает ненужные больше отношения смежности, если таковые имеются.
Когда маршрутизатор подключается к сети, сначала он достигает состояния 2-WAY со всеми своими соседями, а потом, прежде чем приступать к выборам, ожидает время WAIT. В течение этого времени он передает Hello-сообщения с обнуленными полями DR и BDR. После истечения периода WAIT вновь подключившийся маршрутизатор может предлагать себя на роль BDR , производить выборы и формировать отношения смежности.
Сообщение "Обновление состояния связей (Link State Update)"

Сообщение "Обновление состояния связей" собственно и содержит информацию из базы данных состояния связей. Это сообщение отправляется в ответ на запрос (тип 3) при работе протокола обмена (см. ), а также при работе протокола затопления (см. )для распространения информации об изменении состояния связей. В последнем случае его получение подтверждается сообщениями типа 5 "Link State Acknowledgment", в случае отсутствия подтверждения посылка повторяется.
Сообщение типа 4 состоит из одного или нескольких объявлений о состоянии связей (Link State Advertisement, LSA), следующих друг за другом. Существует несколько типов LSA. Каждое LSA состоит из заголовка и тела. Типы LSA и их формат будут рассмотрены в следующих пунктах этого раздела (пп. - ).
Число объявлений LSA в сообщении определяется первым 32-битным словом, следующим за OSPF заголовком. Длина каждого LSA определяется соответствующим полем в заголовке LSA. Если все LSA, которые требуется отправить, не помещаются в одно сообщение, они могут быть распределены по нескольким сообщениям.
Дейтаграмма с OSPF сообщением типа 4, несущим 3 LSA, имеет следующую общую структуру:

Сообщение "Подтверждение приема сообщения о состоянии связей (Link State Acknowledgment)"
Сообщения типа 5 отправляются в подтверждение получения сообщений типа 4 при работе протокола затопления. Сообщение содержит одно или несколько подтверждений, каждое подтверждение состоит из заголовка LSA (см. ), получение которого подтверждается.
Маршрутизатор может не посылать подтверждение на каждое сообщение типа 4, а послать одно сообщение типа 5 с подтверждениями на получение LSA, присланных в нескольких сообщениях типа 4, но в любом случае задержка с посылкой подтверждений не должна быть велика.
Число подтверждений в одном сообщении типа 5 определяется из общей длины сообщения, указанной в OSPF-заголовке.
Сообщение "Запрос состояния связи (Link State Request)"
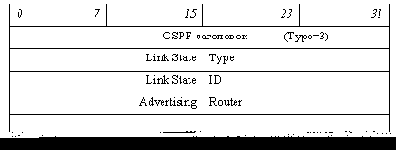
Сообщение "Запрос состояния связи" отправляется при работе протокола обмена (см. ) после того, как был произведен обмен описаниями баз данных.
Сообщение содержит один или несколько идентификаторов записей, которые маршрутизатор хочет получить от своего соседа. Каждый идентификатор записи состоит из полей "Link State Type", "Link State ID" и "Advertising Router"; значения этих полей будут рассмотрены при обсуждении заголовков объявлений о состоянии связей (LSA) в . Число идентификаторов (то есть число запросов) в одном сообщении определяется из общей длины сообщения, указанной в OSPF-заголовке.
Подтверждением приема запроса является посылка сообщения типа 4 "Обновление состояния связи". При отсутствии подтверждения в течение некоторого тайм-аута запрос посылается повторно. Если все запросы не могут быть помещены в одно сообщение, они разбиваются на несколько сообщений, но каждое следующее сообщение-запрос посылается только после получения всех записей, запрошенных в предыдущем.
Создание статических маршрутов
Таблица маршрутов может заполняться различными способами. Статическая маршрутизация применяется в том случае, когда используемые маршруты не могут измениться в течение времени, например, для выше обсужденных хоста и маршрутизатора, где просто отсутствуют какие-либо альтернативные маршруты. Статические маршруты конфигурируются администратором сети или конкретного узла.
Для рядового хоста из рассмотренного выше примера достаточно указать только адрес шлюза (следующего маршрутизатора в маршруте по умолчанию), остальные записи в таблице очевидны, и хост, зная свой собственный IP-адрес и сетевую маску, может внести их самостоятельно. Адрес шлюза может быть указан как вручную, так и получен автоматически при конфигурировании стека TCP/IP через DHCP сервер (см. лабораторную работу в курсе ).
Стек протоколов TCP/IP
TCP/IP - собирательное название для набора (стека) сетевых протоколов разных уровней, используемых в Интернет. Особенности TCP/IP:
открытые стандарты протоколов, разрабатываемые независимо от программного и аппаратного обеспечения; независимость от физической среды передачи; система уникальной адресации; стандартизованные протоколы высокого уровня для распространенных пользовательских сервисов.
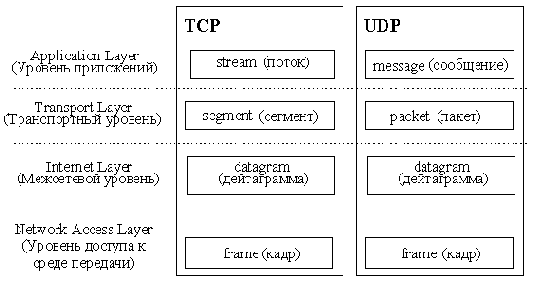
Рис. 1.2.1. Стек протоколов TCP/IP
Стек протоколов TCP/IP делится на 4 уровня: прикладной (application), транспортный (transport), межсетевой (internet) и уровень доступа к среде передачи (network access). Термины, применяемые для обозначения блока передаваемых данных, различны при использовании разных протоколов транспортного уровня - TCP и UDP, поэтому на рисунке 1.2.1 изображено два стека. Как и в модели OSI, данные более верхних уровней инкапсулируются в пакеты нижних уровней (см. рис. 1.2.2).

Рис. 1.2.2. Пример инкапсуляции пакетов в стеке TCP/IP
Примерное соотношение уровней стеков OSI и TCP/IP показано на рис. 1.2.3.

Рис. 1.2.3. Соотношение уровней стеков OSI и TCP/IP
Ниже кратко рассматриваются функции каждого уровня и примеры протоколов. Программа, реализующая функции того или иного протокола, часто называется модулем, например, “IP-модуль”, “модуль TCP”.
Таблицы маршрутов
Рассмотрим примеры маршрутных таблиц, с которыми имеет дело администратор локальной сети 194.84.124.0/24.
Таблица маршрутов рядового хоста с адресом 194.84.124.4 (хост В на рис. 2.3.2):
Таблица 2.3.1
Destination
Значения флагов: U (Up) - маршрут работает; H (Host) - пунктом назначения является отдельный узел (хост), а не сеть; G (Gateway) - маршрут к сети назначения проходит через один или несколько промежуточных маршрутизаторов. Интерфейс le0 обозначает Ethernet, lo0 - интерфейс обратной связи (loopback).
Значение первой записи очевидно, вторая запись определяет, что дейтаграммы, адресованные в локальную сеть, хост отправляет самостоятельно через свой интерфейс le0. Третья запись (маршрут по умолчанию) устанавливает, что все остальные дейтаграммы передаются на адрес 194.84.124.1, который является адресом следующего маршрутизатора (флаг G), для дальнейшей пересылки. Чтобы определить способ достижения самого маршрутизатора, следует, очевидно, обратиться ко второй строке таблицы, так как адрес маршрутизатора принадлежит сети 194.84.124.0.
Заметим, что в этой таблице для простоты опущены маски сетей.
Пример таблицы маршрутов маршрутизатора, соединяющего локальную сеть с провайдером Интернет по выделенному каналу (G1 на ):
Таблица 2.3.2
Destination
В таблице явно показаны маски сетей.
Первые две записи говорят о том, что маршрутизатор самостоятельно, через свои соответствующие IP-интерфейсы отправляет дейтаграммы, адресованные в сети, к которым он подключен непосредственно. Все остальные дейтаграммы перенаправляются к G2 (194.84.0.118). Интерфейс se0 обозначает последовательный (serial) канал - выделенную линию.
"Телекоммуникационные технологии (Сети TCP/IP)"
Список литературы
М.А.Мамаев. Телекоммуникационные технологии: Сети ТСP/IP. Учебное пособие - Владивосток: Изд-во ВГУЭиС, 1999.
М.Мамаев, С. Петренко. Технологии защиты информации в Интернете. Специальный справочник - СПб: "Питер", 2002.
А.Леинванд, Б.Пински. Конфигурирование маршрутизаторов Cisco. 2-е издание - М.: "Вильямс", 2001.
В.Олифер, Н.Олифер. Компьютерные сети. Принципы, технологии, протоколы - СПб: "Питер", 2001.
Э. Немет, Г. Снайдер, С. Сибасс, Т. Хейн. UNIX: руководство системного администратора. Для професcионалов - СПб: "Питер", 2002.
Й.Снейдер. Эффективное программирование TCP/IP. Библиотека программиста - СПб: "Питер", 2002.
А.М.Робачевский. Операционная система UNIX. - Спб.: BHV - Санкт-Петербург, 1997.
М. Кульгин. Технологии корпоративных сетей. Энциклопедия - СПб.: Питер, 1999.
Ресурсы on-line
Библиотека Афины
: описания, документация, руководства.
первый октет обнулен за исключением

Значения полей:
VEB(3 бита) - первый октет обнулен за исключением трех старших бит V (бит 5), E (бит 6) и B (бит 7). Установленные значения этих бит говорят о том, что маршрутизатор, объявивший данное LSA, является:
бит B - пограничным маршрутизатором области (ABR);
бит Е - пограничным маршрутизатором системы (ASBR);
бит V - оконечной точкой виртуальной связи.
Число связей (2 октета) - число связей, объявленных в данном LSA.
Объявление о каждой связи состоит из полей "Link ID", "Link Data", "Type", "#TOS", "TOS 0 metric", за которыми может следовать 0 или более 32-разрядных слов, состоящих из полей "TOS", нулевого октета и "TOS metric". Количество таких слов определяется полем "#TOS".
Link ID (4 октета), Link Data (4 октета), Type (1 октет) - интерпретация полей "Link ID" и "Link Data" зависит от значения поля "Type" (ниже в колонке "Link Data" под IP-адресом понимается IP-адрес интерфейса объявляющего маршрутизатора, подключенного к той связи, которую он объявляет):
#TOS (1 октет) - число метрик для маршрутизации по типу сервиса для данной связи (0 - метрики для маршрутизации по типу сервиса не определены).
TOS 0 metric (2 октета) - метрика данной связи для маршрутизации без учета типа сервиса (метрика по умолчанию).
TOS (1 октет), TOS metric (2 октета) - метрика данной связи ("TOS metric") для указанного типа сервиса ("TOS"). Число таких метрик определено полем "#TOS" и может быть равно нулю. Значение TOS определяется, как в заголовке IP-дейтаграммы. Несмотря на то, что маршрутизация по типу сервиса исключена из последней версии стандарта OSPF, эти поля поддерживаются для совместимости с предыдущими версиями.
Кроме собственно связей с тупиковыми сетями, следующие связи объявляются как связи с тупиковыми сетями:
связь с собственным интерфейсом (интерфейсами) типа loopback (Link ID=IP-адрес интерфейса, Link Data заполняется единицами); cвязь с хостом, подключенным к маршрутизатору по двухточечной линии (Link ID=IP-адрес хоста, Link Data заполняется единицами); связь с сетью, представляющей собой двухточечное соединение между маршрутизаторами (в дополнение к собственно двухточечной связи между маршрутизаторами); в случае, если этой сети не присвоены адрес и маска, Link ID равен IP-адресу интерфейса соседнего маршрутизатора, Link Data заполняется единицами; связь с собственным интерфейсом, подключенным к соединению типа point-to-multipoint (в дополнение к двухточечным связям с каждым из соседей, подключенным к этому соединению); Link ID=IP-адрес интерфейса, Link Data заполняется единицами.
к сети множественного доступа. Перечисляются
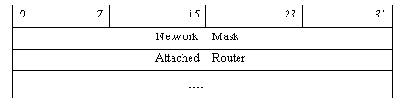
Значения полей:
Network Mask (4 октета) - маска сети множественного доступа (адрес этой сети указан в поле "Link State ID" заголовка LSA).
Attached Router (4 октета) - идентификатор маршрутизатора, подключенного к сети множественного доступа. Перечисляются все маршрутизаторы, установившие отношения смежности с выделенным маршрутизатором. Длина списка маршрутизаторов определяется из общей длины LSA, указанной в заголовке LSA.
LSA этого типа описывает связи, направленные в графе системы от вершины типа "транзитная сеть" к маршрутизаторам этой сети. Метрика этих связей не указывается, поскольку она считается равной нулю.
Далее следует одна или более

Значения полей:
Network Mask (4 октета) - маска внешней IP-сети. IP-адрес этой сети указан в поле "Link State ID" заголовка LSA.
Далее следует одна или более записей с указанием метрики и других характеристик маршрута до данной сети для разных типов сервиса (поля "E TOS", "TOS metric", "Forwarding Address", "External Route Tag"). Первыми указываются характеристики для TOS=0 (т.е. когда тип сервиса не учитывается), эта часть присутствует обязательно. Число прочих типов сервиса, представленных в LSA, определяется из общей длины LSA, указанной в заголовке LSA. Несмотря на то, что маршрутизация по типу сервиса исключена из последней версии стандарта OSPF, соответствующие поля поддерживаются для совместимости с предыдущими версиями.
E (E TOS) - младший бит октета, содержащего значение TOS (самим значением TOS используются биты 3-6). Имеет следующие значения:
Е установлен a
метрика внешнего маршрута исчисляется в единицах, не сравнимых с исчислением метрик в OSPF (протоколы внешней маршрутизации, поставляющие данные о внешних маршрутах, не обязаны использовать совместимые с OSPF значения метрик); в этом случае метрика, указанная для соответствующего TOS, должна считаться больше любой метрики в OSPF-системе;
Е сброшен a
метрика внешнего маршрута может складываться с метриками внутренних маршрутов.
TOS 0 metric (TOS metric) (2 октета) - метрика для соответствующего значения TOS.
Forwarding Address (4 октета) - адрес маршрутизатора, которому следует пересылать дейтаграммы, адресованные в объявляемую внешнюю сеть. Это поле используется, когда ASBR считает, что он сам - не лучший "следующий маршрутизатор" на пути в данную внешнюю сеть. Например, в одной IP-сети с ASBR находится маршрутизатор G, не поддерживающий протокол OSPF (а поддерживающий, например, BGP), причем через G лежат кратчайшие маршруты к определенным внешним сетям. ASBR, который также поддерживает и BGP, узнаёт от G об этих маршрутах и объявляет их в автономной системе, однако с помощью "Forwarding Address" он тут же указывает, что дейтаграммы, адресованные в эти сети, лучше сразу же направлять маршрутизатору G.
Возможны и другие примеры.
Если поле "Forwarding Address" обнулено, то дейтаграммы следует пересылать тому ASBR, который объявил данное LSA.
External Route Tag (4 октета) - поле, используемое ASBR для целей внешней маршрутизации; модулем OSPF игнорируется.
Если возможно, адреса нескольких внешних сетей агрегируются в общий адрес с более короткой маской, что уменьшает количество LSA и размер базы данных.
о расстоянии только до одной

LSA типа 3 или 4 содержит объявление о расстоянии только до одной IP-сети, лежащей за пределами области (до одного пограничного маршрутизатора). Адрес сети или идентификатор маршрутизатора указан в поле "Link State ID" заголовка LSA.
Поле "Network Mask" (4 октета) содержит значение маски сети, если это LSA типа 3, или все единицы, если это LSA типа 4. Далее следует 32-битное слово, два последних октета которого содержат метрику расстояния по умолчанию (тип сервиса 0), после которого может следовать 0 или более 32-битных слов, объявляющих метрики расстояний для маршрутизации по типам сервиса- аналогично тому, как это сделано в LSA типа 1. Несмотря на то, что маршрутизация по типу сервиса исключена из последней версии стандарта OSPF, эти поля поддерживаются для совместимости с предыдущими версиями.
Поле "#TOS" здесь отсутствует, т.к. число объявлений метрик для типов сервиса можно вычислить из общей длины LSA, указанной в заголовке LSA.
LSA типа 3 и 4 распространяются областными пограничными маршрутизаторами как внутри периферийных областей, так и в магистрали. LSA, распространяемые в периферийной области, содержат информацию о достижимости сетей и ASBR, находящихся в магистрали и других периферийных областях. LSA, распространяемые в магистрали, содержат информацию о достижимости сетей и ASBR, находящихся в периферийной области.
Если возможно, адреса нескольких сетей агрегируются в общий адрес с более короткой маской, что уменьшает количество LSA и размер базы данных.
Типы BGP-сообщений
OPEN – посылается после установления TCP-соединения. Ответом на OPEN является сообщение KEEPALIVE, если вторая сторона согласна стать BGP-соседом; иначе посылается сообщение NOTIFICATION с кодом, поясняющим причину отказа, и соединение разрывается.
KEEPALIVE – сообщение предназначено для подтверждения согласия установить соседские отношения, а также для мониторинга активности открытого соединения: для этого BGP-соседи обмениваются KEEPALIVE-сообщениями через определенные интервалы времени.
UPDATE – сообщение предназначено для анонсирования и отзыва маршрутов. После установления соединения с помощью сообщений UPDATE пересылаются все маршруты, которые маршрутизатор хочет объявить соседу (full update), после чего пересылаются только данные о добавленных или удаленных маршрутах по мере их появления (partial update).
NOTIFICATION – сообщение этого типа используется для информирования соседа о причине закрытия соединения. После отправления этого сообщения BGP-соединение закрывается.
Типы и формат сообщений
В протоколе RIP имеются два типа сообщений, которыми обмениваются маршрутизаторы:
ответ (response)- рассылка вектора расстояний;
запрос (request) - маршрутизатор (например, после своей загрузки) запрашивает у соседей их маршрутные таблицы или данные об определенном маршруте.
Обмен сообщениями происходит по порту 520 UDP.
Формат сообщений обоих типов одинаков:
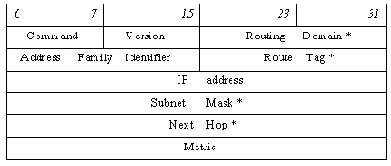
Поля, помеченные знаком *, относятся к версии 2; в сообщениях RIP-1 эти поля должны быть обнулены.
Сообщение RIP состоит из 32-битного слова, определяющего тип сообщения и версию протокола (плюс "Routing Domain" в версии 2), за которым следует набор из одного и более элементов вектора расстояний. Каждый элемент вектора расстояний занимает 5 слов (20 октетов) (от начала поля "Address Family Identifier" до конца поля "Metric" включительно). Максимальное число элементов вектора - 25, если вектор длиннее, он может разбиваться на несколько сообщений.
Поле "Command" определяет тип сообщения: 1 - request, 2 - response; поле "Version" - версию протокола (1 или 2).
Поле "Address Family Identifier" содержит значение 2, которое обозначает семейство адресов IP; другие значения не определены. Поля "IP address" и "Metric" содержат адрес сети и расстояние до нее.
Дополнительно к полям версии 1 во второй версии определены следующие.
"Routing Domain" - идентификатор RIP-системы, к которой принадлежит данное сообщение; часто - номер автономной системы. Используется, когда к одному физическому каналу подключены маршрутизаторы из нескольких автономных систем, в каждой автономной системе поддерживается своя таблица маршрутов. Поскольку сообщения RIP рассылаются всем маршрутизаторам, подключенным к сети, требуется различать сообщения, относящиеся к "своей" и "чужой" автономным системам.
"Route Tag" - используется как метка для внешних маршрутов при работе с протоколами внешней маршрутизации.
"Subnet Mask" - маска сети, адрес которой содержится в поле IP address. RIP-1 работает только с классовой моделью адресов.
"Next Hop" - адрес следующего маршрутизатора для данного маршрута, если он отличается от адреса маршрутизатора, пославшего данное сообщение. Это поле используется, когда к одному физическому каналу подключены маршрутизаторы из нескольких автономных систем и, следовательно, некоторые маршрутизаторы "чужой" автономной системы физически могут быть достигнуты напрямую, минуя пограничный (логически подключенный к обеим автономным системам) маршрутизатор. Об этом пограничный маршрутизатор и объявляет в поле "Next Hop".
Адрес 0.0.0.0 в сообщении типа "ответ" обозначает маршрут, ведущий за пределы RIP-системы. В сообщении типа "запрос" этот адрес означает запрос информации о всех маршрутах (полного вектора расстояний). Указание в сообщении типа "запрос" адреса конкретной сети означает запрос элемента вектора расстояний только для этой сети - такой режим используется обычно только в отладочных целях.
Аутентификация может производиться протоколом RIP-2 для обработки только тех сообщений, которые содержат правильный аутентификационный код. При работе в таком режиме первый 20-октетный элемент вектора расстояний, следующий непосредственно за первым 32-битным словом RIP-сообщения, является сегментом аутентификации. Он определяется по значению поля "Address Family Identifier", равному в этом случае 0xFFFF. Следующие 2 октета этого элемента определяют тип аутентификации, а остальные 16 октетов содержат аутентификационный код. Таким образом, в RIP-сообщении с аутентификацией может передаваться не 25, а только 24 элемента вектора расстояний, которые следуют за сегментом аутентификации. К настоящему моменту надежного алгоритма аутентификации для протокола RIP не разработано; стандартом определена только аутентификация с помощью обычного пароля (значение поля "Тип" равно 2).
Типы Объявлений о состоянии связей (LSA)
Тип 1. Router Links Advertisement- маршрутизатор объявляет о своих связях с соседними маршрутизаторами, транзитными и тупиковыми сетями; распространяется каждым маршрутизатором внутри области, к которой принадлежат эти связи.
Тип 2. Network Links Advertisement - содержит список маршрутизаторов, подключенных к сети множественного доступа; распространяется выделенным маршрутизатором внутри области, к которой принадлежит данная сеть. Фактически описывает связи, направленные в графе системы от вершины типа "транзитная сеть" к маршрутизаторам этой сети.
Тип 3. Summary Link Advertisement - описывает расстояние от данного областного пограничного маршрутизатора (ABR) до IP-сети, находящейся за пределами данной области, но принадлежащей данной OSPF-системе; распространяется этим ABR внутри области.
Тип 4. AS Boundary Router Summary Link Advertisement - описывает расстояние от данного ABR до данного пограничного маршрутизатора системы (ASBR); распространяется этим ABR внутри области.
Тип 5. AS External Link Advertisement - описывает расстояние до сети, находящейся за пределами OSPF-системы; распространяется ASBR и ретранслируется во все области, кроме тупиковых, их пограничными маршрутизаторами.
Тип 7. AS External Link Advertisement (NSSA) - то же, что тип 5, но распространяется внутри (в них распространение LSA типа 5 запрещено); на границе NSSA и магистрали преобразуется в LSA типа 5 для дальнейшего распространения в системе. Формат идентичен формату LSA типа 5 за исключением номера типа.
Транспортный уровень
Протоколы транспортного уровня обеспечивают прозрачную (сквозную) доставку данных (end-to-end delivery service) между двумя прикладными процессами. Процесс, получающий или отправляющий данные с помощью транспортного уровня, идентифицируется на этом уровне номером, который называется номером порта. Таким образом, роль адреса отправителя и получателя на транспортном уровне выполняет номер порта (или проще- порт).
Анализируя заголовок своего пакета, полученного от межсетевого уровня, транспортный модуль определяет по номеру порта получателя, какому из прикладных процессов направлены данные, и передает эти данные соответствующему прикладному процессу (возможно, после проверки их на наличие ошибок и т.п.). Номера портов получателя и отправителя записываются в заголовок транспортным модулем, отправляющим данные; заголовок транспортного уровня содержит также и другую служебную информацию; формат заголовка зависит от используемого транспортного протокола.
На транспортном уровне работают два основных протокола: UDP и TCP.
TCP (Transmission Control Protocol - протокол контроля передачи) - надежный протокол с установлением соединения: он управляет логическим сеансом связи (устанавливает, поддерживает и закрывает соединение) между процессами и обеспечивает надежную (безошибочную и гарантированную) доставку прикладных данных от процесса к процессу.
Данными для TCP является не интерпретируемая протоколом последовательность пользовательских октетов, разбиваемая для передачи по частям. Каждая часть передается в отдельном TCP-сегменте. Для продвижения сегмента по сети между компьютером-отправителем и компьютером-получателем модуль TCP пользуется сервисом межсетевого уровня (вызывает модуль IP).
Более подробно работа протокола TCP рассматривается в .
Все приложения, приведенные как пример в предыдущем пункте, пользуются услугами TCP.
Протокол UDP
UDP (User Datagram Protocol, протокол пользовательских дейтаграмм) фактически не выполняет каких-либо особых функций дополнительно к функциям межсетевого уровня (протокола IP, см. и ). Протокол UDP используется либо при пересылке коротких сообщений, когда накладные расходы на установление сеанса и проверку успешной доставки данных оказываются выше расходов на повторную (в случае неудачи) пересылку сообщения, либо в том случае, когда сама организация процесса-приложения обеспечивает установление соединения и проверку доставки пакетов (например, NFS).
Пользовательские данные, поступившие от прикладного уровня, предваряются UDP-заголовком, и сформированный таким образом UDP-пакет отправляется на межсетевой уровень.
UDP-заголовок состоит из двух 32-битных слов:
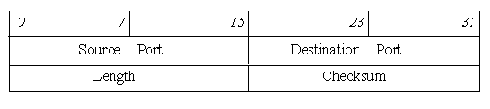
Значения полей:
Source Port - номер порта процесса-отправителя.
Destination Port - номер порта процесса-получателя.
Length - длина UDP-пакета вместе с заголовком в октетах.
Checksum - контрольная сумма. Контрольная сумма вычисляется таким же образом, как и в TCP-заголовке (см. ); если UDP-пакет имеет нечетную длину, то при вычислении контрольной суммы к нему добавляется нулевой октет.
После заголовка непосредственно следуют пользовательские данные, переданные модулю UDP прикладным уровнем за один вызов. Протокол UDP рассматривает эти данные как целостное сообщение; он никогда не разбивает сообщение для передачи в нескольких пакетах и не объединяет несколько сообщений для пересылки в одном пакете. Если прикладной процесс N раз вызвал модуль UDP для отправки данных (т.е. запросил отправку N сообщений), то модулем UDP будет сформировано и отправлено N пакетов, и процесс-получатель будет должен N раз вызвать свой модуль UDP для получения всех сообщений.
При получении пакета от межсетевого уровня модуль UDP проверяет контрольную сумму и передает содержимое сообщения прикладному процессу, чей номер порта указан в поле “Destination Port”.
Если проверка контрольной суммы выявила ошибку или если процесса, подключенного к требуемому порту, не существует, пакет игнорируется. Если пакеты поступают быстрее, чем модуль UDP успевает их обрабатывать, то поступающие пакеты также игнорируются. Протокол UDP не имеет никаких средств подтверждения безошибочного приема данных или сообщения об ошибке, не обеспечивает приход сообщений в порядке отправки, не производит предварительного установления сеанса связи между прикладными процессами, поэтому он является ненадежным протоколом без установления соединения. Если приложение нуждается в подобного рода услугах, оно должно использовать на транспортном уровне протокол TCP.
Максимальная длина UDP-сообщения равна максимальной длине IP-дейтаграммы (65535 октетов) за вычетом минимального IP-заголовка (20) и UDP-заголовка (8), т.е. 65507 октетов. На практике обычно используются сообщения длиной 8192 октета.
Примеры прикладных процессов, использующих протокол UDP: NFS (Network File System - сетевая файловая система), TFTP (Trivial File Transfer Protocol - простой протокол передачи файлов), SNMP (Simple Network Management Protocol - простой протокол управления сетью), DNS (Domain Name Service - доменная служба имен).
Туннелирование
Предположим, злоумышленник хочет отправить данные с узла Х узлу А, находящемуся за пределами его сети, однако правила фильтрации на маршрутизаторе запрещают отправку датаграмм узлу А (рис. 9.11). В то же время разрешена отправка датаграмм узлу В, также находящемуся за пределами охраняемой сети.
Злоумышленник использует узел В как ретранслятор датаграмм, направленных в А. Для этого он создает датаграмму, направленную из Х в В, в поле Protocol которой помещается значение 4 («IP»), а в качестве данных эта датаграмма несет другую IP-датаграмму, направленную из Х в А. Фильтрующий маршрутизатор пропускает сформированную датаграмму, поскольку она адресована разрешенному узлу В, а IP-модуль узла В извлекает из нее вложенную датаграмму. Видя, что вложенная датаграмма адресована не ему, узел В отправляет ее по назначению, то есть узлу А (рис. 9.11).
Описанная операция называется туннелированием. Для ее осуществления злоумышленник может иметь, а может и не иметь сговора с узлом В — в зависимости от того, что представляет собой этот узел и как он сконфигурирован. Если В является маршрутизатором, то он может обрабатывать вложенные датаграммы без всякого сговора со злоумышленником, если только администратор не заблокировал такую возможность.
Того же самого результата можно добиться, применив IP-опцию Loose/Strict Source Routing.
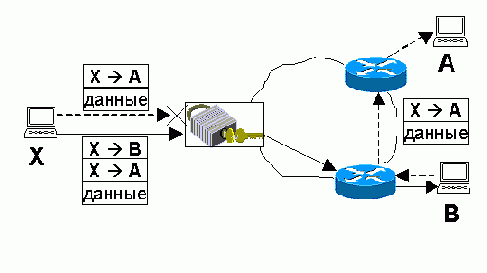
Рис. 9.11. Туннелирование сквозь фильтрующий маршрутизатор
Отметим, что адрес отправителя датаграммы скрыть нельзя, поэтому, если маршрутизатор не пропускает также датаграммы, идущие из А, то есть осуществляет фильтрацию по адресу отравителя, то обмануть его вышеописанным способом невозможно. В этом случае злоумышленник имеет только одностороннюю связь с узлом А.
Очевидно, что туннелирование может использоваться и в обратном направлении, то есть, для проникновения из Интернета внутрь охраняемой сети. При этом узел Х находится в Интернете, а узлы А и В — в охраняемой сети и узлу В разрешено получение датаграмм из внешних сетей.
Для защиты от туннелирования следует запретить маршрутизатору транслировать во внешнюю сеть датаграммы с полем Protocol=4 и датаграммы с опциями. Напомним, что туннелирование используется для подключения сетей, поддерживающих групповую рассылку, к сети MBONE через сети, не поддерживающие групповую маршрутизацию. В этом случае все маршрутизаторы защищаемой (внутренней) системы сетей должны поддерживать групповую маршрутизацию, а инкапсуляция и извлечение групповых датаграмм должны выполняться непосредственно на фильтрующем маршрутизаторе.
Тупиковые и не совсем тупиковые области
Число внешних маршрутов, которые пограничные маршрутизаторы автономной системы объявляют в системе, может быть очень велико, потому что в общем случае эти маршруты должны описывать путь до любой сети в Интернет. Для многих периферийных областей, особенно имеющих только один ABR, знать и обрабатывать все эти маршруты представляется избыточным. Внутренним маршрутизаторам области для отправки данных, адресованных вовне автономной системы, достаточно пересылать их пограничному маршрутизатору области, а тот уже, на основании всей информации о внешних маршрутах, будет принимать решения, через какой из пограничных маршрутизаторов системы отправить эти данные.
Области, внутрь которых не передается информация о внешних маршрутах (см. ), называются тупиковыми областями (stub areas). Все дейтаграммы, исходящие из данной области и адресованные за пределы автономной системы, отправляются по маршруту по умолчанию (default) через определенный ABR. Тупиковая область может иметь несколько ABR, но для каждого узла внутри области установлен маршрут по умолчанию, проходящий только через один их ABR.
Данные о достижимости сетей своей автономной системы объявляются в тупиковую область ее пограничными маршрутизаторами, как и в обычную область. Однако и эта информация может оказаться избыточной (например, если тупиковая область имеет всего один ABR). Тогда маршрут по умолчанию распространяется не только на дейтаграммы, адресованные за пределы автономной системы, но и на дейтаграммы, адресованные за пределы области.
В тупиковой области не могут находиться пограничные маршрутизаторы автономной системы. Через тупиковую область не может проходить виртуальная связь.
Протокол OSPF определяет также понятие не совсем тупиковых областей (not so stubby area, NSSA). К таким областям относятся тупиковые области, в которых разрешено объявлять некоторые внешние маршруты. Рассмотрим автономные системы, изображенные на рис. 5.4.3.
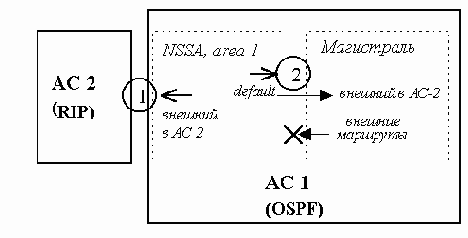
Рис. 5.4.3. Пример NSSA
Толстые стрелки описывают объявление (экспорт) маршрутов, тонкие- сами маршруты.
К области 1, входящей в АС 1, подключена небольшая автономная система 2, маршрутизируемая по RIP. Объявление области 1 как не совсем тупиковой позволяет, с одной стороны, не экспортировать в нее все внешние маршруты, ведущие из АС 1 и объявленные в магистрали, заменив их, как и в тупиковой области, маршрутом по умолчанию (default). С другой стороны, есть возможность сделать исключение, а именно, объявить внутри области 1 внешний маршрут в АС 2 через ASBR ?
и экспортировать это объявление в остальную часть АС 1 через ABR ?
.
Внешние маршруты, которые можно объявлять в NSSA, отличаются от остальных внешних маршрутов (которые не объявляются, а сводятся в маршрут по умолчанию) тем, что объявление о них имеет специальный тип (см. ).
Уменьшение числа отношений смежности
Очевидно, такое буквальное следование идеологии не является рациональным. Протокол OSPF сводит ситуацию только к N отношениям смежности, выбирая среди всех маршрутизаторов данной широковещательной сети один выделенный маршрутизатор (designated router, DR), с которым все остальные маршрутизаторы устанавливают отношения смежности.
Это значит, что каждый "невыделенный" маршрутизатор поддерживает синхронизацию базы данных состояния связей не со всеми соседями, а только с выделенным маршрутизатором. При этом протокол затопления в подобной сети работает следующим образом: "обычный" маршрутизатор сообщает об изменении состояния своих связей выделенному маршрутизатору, а тот затапливает сеть этим сообщением и его получают все остальные маршрутизаторы сети. Естественно, что по своим внешним интерфейсам, ведущим к прочим маршрутизаторам системы, не находящимся в данной сети множественного доступа, каждый маршрутизатор отправляет сообщения без участия выделенного маршрутизатора.
Уменьшение размера базы данных
Протокол OSPF позволяет также редуцировать размер базы данных состояния связей. Для этого в граф системы вводится виртуальная вершина "транзитная сеть", представляющая собой сеть множественного доступа как таковую. Каждый маршрутизатор, в том числе и выделенный, при таком подходе имеет не набор двухточечных связей со всеми остальными маршрутизаторами своей сети, а одну связь с вершиной "транзитная сеть". Таким образом, в базу данных вносится всего 2N, а не N2 записей: N записей о связях, идущих от маршрутизаторов к вершине "транзитная сеть", и столько же связей, идущих в обратном направлении.
За поддержку в базе данных записей о связях, идущих от маршрутизаторов, отвечают, как и положено, сами маршрутизаторы. Эти связи имеют метрику, равную метрике сети (например, 10 в случае 10Base-T Ethernet).
За поддержку связей, идущих от транзитной сети к маршрутизаторам, отвечает выделенный маршрутизатор (см. также ). Такие связи имеют нулевую метрику, это связано с тем, что при такой модели маршрут между двумя маршрутизаторами А и В в сети T проходит через вершину "транзитная сеть Т", то есть его метрика равна сумме метрик связей АТ и ТВ. Очевидно, что метрика этого маршрута должна быть равна метрике сети, но метрика связи АТ уже равна метрике сети, следовательно, метрика связи ВТ должна быть нулевой.
Управление потоком
Для ускорения и оптимизации процесса передачи больших объемов данных протокол TCP определяет метод управления потоком, называемый методом скользящего окна, который позволяет отправителю посылать очередной сегмент, не дожидаясь подтверждения о получении в пункте назначения предшествующего сегмента.
Протокол TCP формирует подтверждения не для каждого конкретного успешно полученного пакета, а для всех данных от начала посылки до некоторого порядкового номера ACK SN (Acknowledge Sequence Number) исключительно. В качестве подтверждения успешного приема, например, первых 2000 байт, высылается ACK SN = 2001: это означает, что все данные в байтовом потоке под номерами от ISN+1=1 до данного ACK SN -1 (2000) успешно получены (см. рис. 3.1.2).
Рис. 3.1.2. Метод скользящего окна
Вместе с посылкой отправителю ACK SN получатель объявляет также “размер окна”, например - 6000. Это значит, что отправитель может посылать данные с порядковыми номерами от текущего ACK SN = 2001 до (ACK SN + размер окна -1) = 8000, не дожидаясь подтверждения со стороны получателя. Допустим, в данный момент отправитель посылает тысячеоктетный сегмент с порядковым номером данных SN=4001. Если не будет получено новое подтверждение (новый ACK SN), отправитель будет посылать данные, пока он остается в пределах объявленного окна, то есть до номера 8001. После этого посылка данных будет прекращена до получения очередного подтверждения и (возможно) нового размера окна. Однако размер окна выбирается таким образом, чтобы подтверждения успевали приходить вовремя и остановки передачи не происходило - для этого и предназначен метод скользящего окна. Размер окна может динамически изменяться получателем.
Для временной остановки посылки данных достаточно объявить нулевое окно. Но даже и в этом случае через определенные промежутки времени будут отправляться сегменты с одним октетом данных. Это делается для того, чтобы отправитель гарантированно узнал о том, что получатель вновь объявил ненулевое окно, поскольку получатель обязан подтвердить получение “пробных” сегментов, а в этих подтверждениях он укажет также и текущий размер своего окна.
Как уже было сказано выше, протокол TCP позволяет вести полнодуплексную передачу. Один и тот же сегмент, высылаемый, например, из В в А, может содержать в заголовке служебную информацию по подтверждению получения данных от А, а в поле данных - полезные данные для А.
Модуль TCP может оптимизировать максимальный размер сегмента исходя из значений MTU на разных участках маршрута (см. также , "Path MTU Discovery") и других характеристик соединения.
Модуль TCP может использовать алгоритм "медленного старта", формируя при установлении соединения окно перегрузки, размер которого изначально равен размеру одного сегмента. Это окно показывает, сколько сегментов TCP-модуль, с его собственной точки зрения, может отправить без получения подтверждения. Скользящее же окно, рассмотренное выше, показывает, какой объем неподтвержденных данных модулю разрешено отправить с точки зрения удаленного модуля, получателя его данных. После прихода подтверждения от получателя окно перегрузки увеличивается на 1 сегмент, и отправитель может выслать уже два сегмента, не дожидаясь подтверждения. Такой подход позволяет постепенно увеличивать нагрузку на сеть. Если окно перегрузки становится больше скользящего окна, объявляемого получателем, ограничение на передачу неподтвержденных данных устанавливает уже скользящее окно получателя.
В случае, если никакие данные приложениями не передаются, а соединение открыто, модуль TCP может периодически посылать сегменты-зонды для выяснения того, не отключилась ли другая сторона без уведомления партнера (например, в результате обрыва линии или другим некорректным образом). Такое зондирование проводится примерно каждые два часа неактивности.
Управление соединениями
Соединение- это совокупность информации о состоянии потока данных, включающая сокеты, номера посланных, принятых и подтвержденных октетов, размеры окон.
Каждое соединение уникально идентифицируется в Интернет парой сокетов.
Соединение характеризуется для клиента именем, которое является указателем на структуру TCB (Transmission Control Block), содержащую информацию о соединении.
Открытие соединения клиентом осуществляется вызовом функции OPEN, которой передается сокет, с которым требуется установить соединение. Функция возвращает имя соединения. Различают два типа открытия соединения: активное и пассивное.
При активном открытии TCP-модуль начинает процедуру установления соединения с указанным сокетом, при пассивном - ожидает, что удаленный TCP-модуль начнет процедуру установления соединения с указанного сокета. Указание 0.0.0.0:0 в качестве сокета при пассивном открытии означает, что ожидается соединение с любого сокета. Такой способ применяется в демонах - серверах Интернет, которые ждут установления соединения от клиента. Клиент же применяет процедуру активного открытия; сокет при этом формируется из IP-адреса сервера и стандартного номера порта для данного сервиса.
Закрытие соединения клиентом производится с помощью функции CLOSE, которой передается имя соединения.
Процедура установления соединения происходит следующим образом.
Предположим, узел А желает установить соединение с узлом В. Первый отправляемый из А в В TCP-сегмент не содержит полезных данных, а служит для установления соединения. В его заголовке (в поле Flags, см. ) установлен бит SYN, означающий запрос связи, и содержится ISN (Initial Sequence Number - начальный номер последовательности) - число, начиная с которого узел А будет нумеровать отправляемые октеты (например, 0). В ответ на получение такого сегмента узел В откликается посылкой TCP-сегмента, в заголовке которого установлен бит ACK, подтверждающий установление соединения для получения данных от узла А. Так как протокол TCP обеспечивает полнодуплексную передачу данных, то узел В в этом же сегменте устанавливает бит SYN, означающий запрос связи для передачи данных от В к А, и передает свой ISN (например, 0). Полезных данных этот сегмент также не содержит. Третий TCP-сегмент в сеансе посылается из А в В в ответ на сегмент, полученный из В. Так как соединение А -> В можно считать установленным (получено подтверждение от В), то узел А включает в свой сегмент полезные данные, нумерация которых начинается с номера ISN(A)+1. Данные нумеруются по количеству отправленных октетов. В заголовке этого же сегмента узел А устанавливает бит ACK, подтверждающий установление связи B -> A, что позволяет хосту В включить в свой следующий сегмент полезные данные для А.

Рис. 3.1.1. Установка TCP-соединения
Сеанс обмена данными заканчивается процедурой разрыва соединения, которая аналогична процедуре установки, с той разницей, что вместо SYN для разрыва используется служебный бит FIN (“данных для отправки больше не имею”), который устанавливается в заголовке последнего сегмента с данными, отправляемого узлом.
Уровень доступа к среде передачи
Функции этого уровня:
отображение IP-адресов в физические адреса сети (MAC-адреса, например, Ethernet-адрес в случае сети Ethernet). Эту функцию выполняет протокол ARP (см. ); инкапсуляция IP-дейтаграмм в кадры для передачи по физическому каналу и извлечение дейтаграмм из кадров. При этом не требуется какого-либо контроля безошибочности передачи (хотя он может и присутствовать), поскольку в стеке TCP/IP такой контроль возложен на транспортный уровень или на само приложение. В заголовке кадров указывается точка доступа к сервису (SAP, Service Access Point) - поле, содержащее код протокола межсетевого уровня, которому следует передать содержимое кадра (в нашем случае это протокол IP); определение метода доступа к среде передачи - то есть способа, с помощью которого компьютер устанавливает свое право на произведение передачи данных (передача токена, опрос компьютеров, множественный доступ с детектированием коллизий и т.п.). определение представления данных в физической среде; пересылка и прием кадра.
Стек TCP/IP не подразумевает использования каких-либо определенных протоколов уровня доступа к среде передачи и физических сред передачи данных. От уровня доступа к среде передачи требуется наличие интерфейса с модулем IP, обеспечивающего передачу дейтаграммы между уровнями. Также требуется обеспечить преобразование IP-адреса узла сети, на который передается дейтаграмма, в MAC-адрес. Часто в качестве уровня доступа к среде передачи могут выступать целые протокольные стеки, тогда говорят об IP поверх ATM, IP поверх IPX, IP поверх X.25 и т.п.
(С)
Уровень приложений
Приложения, работающие со стеком TCP/IP, могут также выполнять функции уровней представления и частично сеансового модели OSI; например, преобразование данных к внешнему представлению, группировка данных для передачи и т.п.
Распространенными примерами приложений являются программы telnet, ftp, HTTP-серверы и клиенты (WWW-броузеры), программы работы с электронной почтой.
Для пересылки данных другому приложению, приложение обращается к тому или иному модулю транспортного уровня.
Уровни модели OSI
Ниже перечислены (в направлении сверху вниз) уровни модели OSI и указаны их общие функции.
Уровень приложения (Application) - интерфейс с прикладными процессами.
Уровень представления (Presentation) - согласование представления (форматов, кодировок) данных прикладных процессов.
Сеансовый уровень (Session) - установление, поддержка и закрытие логического сеанса связи между удаленными процессами.
Транспортный уровень (Transport) - обеспечение безошибочного сквозного обмена потоками данных между процессами во время сеанса.
Сетевой уровень (Network) - фрагментация и сборка передаваемых транспортным уровнем данных, маршрутизация и продвижение их по сети от компьютера-отправителя к компьютеру-получателю.
Канальный уровень (Data Link) - управление каналом передачи данных, управление доступом к среде передачи, передача данных по каналу, обнаружение ошибок в канале и их коррекция.
Физический уровень (Physical) - физический интерфейс с каналом передачи данных, представление данных в виде физических сигналов и их кодирование (модуляция).
Веерная рассылка (Flooding)
Веерная рассылка – наиболее простой метод маршрутизации групповых дейтаграмм, при котором дейтаграмма рассылается во все сети системы независимо от наличия в той или иной сети членов группы. При поступлении групповой дейтаграммы маршрутизатор проверяет, впервые ли он получает эту дейтаграмму. Если да, то маршрутизатор рассылает дейтаграмму через все свои интерфейсы, кроме того, с которого она была получена. Иначе дейтаграмма игнорируется.
Отметим, что маршрутизатор должен хранить в памяти список всех "недавно" полученных групповых дейтаграмм от каждого источника для каждой группы и производить поиск в этом списке при получении каждой дейтаграммы. При интенсивном групповом трафике это потребует больших затрат памяти и мощности процессора.
Другим существенным недостатком этого метода является то, что групповая дейтаграмма рассылается от источника всеми возможными путями: в некоторые сети дейтаграмма может быть передана несколько раз (разными маршрутизаторами). При этом наличие или отсутствие получателей не принимается в расчет.
Плюсы веерной рассылки: простота реализации, надежность (за счет избыточности), независимость от маршрутных таблиц и протоколов маршрутизации.
Внешние маршруты
Для достижения сетей, не входящих в OSPF-систему (в автономную систему), используются пограничные маршрутизаторы автономной системы (autonomous system border router, ASBR), имеющие связи, уходящие за пределы системы.
ASBR вносят в базу данных состояния связей данные о сетях за пределами системы, достижимых через тот или иной ASBR. Такие сети, а также ведущие к ним маршруты называются внешними (external).
В простейшем случае, если в системе имеется только один ASBR, он объявляет через себя маршрут по умолчанию (default route) и все дейтаграммы, адресованные в сети, не входящие в базу данных системы, отправляются через этот маршрутизатор.
Если в системе имеется несколько ASBR, то, возможно, внутренним маршрутизаторам системы придется выбирать, через какой именно пограничный маршрутизатор нужно отправлять дейтаграммы в ту или иную внешнюю сеть. Это делается на основе специальных записей, вносимых ASBR в базу данных системы. Эти записи содержат адрес и маску внешней сети и метрику расстояния до нее, которая может быть, а может и не быть сравнимой с метриками, используемыми в OSPF-системе (см. также ). Если возможно, адреса нескольких внешних сетей агрегируются в общий адрес с более короткой маской.
ASBR может получать информацию о внешних маршрутах от протоколов внешней маршрутизации, а также все или некоторые внешние маршруты могут быть сконфигурированы администратором (в том числе единственный маршрут по умолчанию).
Внутренний BGP, маршрутные серверы и атрибут NEXT_HOP
Очевидно, что BGP-маршрутизаторы, находящиеся в одной АС, также должны обмениваться между собой маршрутной информацией. Это необходимо для согласованного отбора внешних маршрутов в соответствии с политикой данной АС и для передачи транзитных маршрутов через автономную систему. Такой обмен производится также по протоколу BGP, который в этом случае часто называется IBGP (Internal BGP), (соответственно, протокол обмена маршрутами между маршрутзаторами разных АС обозначается EBGP –External BGP).
Отличие IBGP от EBGP состоит в том, что при объявлении маршрута BGP-соседу, находящемуся в той же самой АС, маршрутизатор не должен добавлять в AS_PATH номер своей автономной системы. Действительно, если номер АС будет добавлен, и сосед анонсирует этот маршрут далее (опять с добавлением номера той же АС), то одна и та же АС будет перечислена AS_PATH дважды, что расценивается как цикл.
Это очевидное правило влечет за собой интересное следствие: чтобы не возникло циклов, маршрутизатор не может анонсировать по IBGP маршрут, полученный также по IBGP, поскольку нет способов определить зацикливание при объявлении BGP-маршрутов внутри одной АС.
Следствием этого следствия является необходимость полного графа IBGP-соединений между пограничными маршрутизаторами одной автономной системы: то есть каждая пара маршрутизаторов должна устанавливать между собой соединение по протоколу IBGP. При этом возникает проблема большого числа соединений (порядка N2, где N-число BGP-маршрутизаторов в АС). Для уменьшения числа соединений применяются различные решения: разбиение АС на конфедерации (подсистемы), применение серверов маршрутной информации и др.
Сервер маршрутной информации (аналог выделенного маршрутизатора в OSPF), обслуживающий группу BGP-маршрутизаторов, работает очень просто: он принимает маршрут от одного участника группы и рассылает его всем остальным. Таким образом, участникам группы нет необходимости устанавливать BGP-соединения попарно; вместо этого каждый участник устанавливает одно соединение с сервером. Группой маршрутизаторов могут быть, например, все BGP-маршрутизаторы данной АС, однако маршрутные серверы могут применяться для уменьшения числа соединений также и на внешних BGP-соединениях – в случае, когда в одной физической сети находится много BGP-маршрутизаторов из различных АС (например, в точке обмена трафиком между провайдерами, рис. 7.2.1.).
Выборы выделенного маршрутизатора
Выборы выделенного маршрутизатора проводятся с помощью протокола Hello (алгоритм выборов описан в ). Кроме выделенного маршрутизатора выбирается также и запасной выделенный маршрутизатор (backup designated router, BDR), остальные маршрутизаторы сети устанавливают отношения смежности как с DR, так и с BDR (следовательно, в предыдущем пункте при описании отношений смежности не хватает BDR). Все сообщения для DR и BDR посылаются по мультикастинговому адресу 224.0.0.6 "Всем выделенным OSPF-маршрутизаторам".
Запасной выделенный маршрутизатор получает эти сообщения, но не предпринимает никаких действий, связанных со своей выделенной функцией. Однако если выделенный маршрутизатор отключается (этот факт детектируется с помощью протокола Hello), то запасной немедленно становится выделенным, не тратя времени на установление отношений смежности с остальными маршрутизаторами, так как эти отношения уже установлены. При этом с помощью протокола Hello выбирается новый запасной выделенный маршрутизатор. Если бывший выделенный маршрутизатор подключится снова, статус выделенного маршрутизатора ему не возвращается.
Зацикливание
К сожалению, поведение дистанционно-векторных протоколов (и в частности, протокола RIP) при изменении топологии системы не всегда корректно и предсказуемо.
Рассмотрим вышеописанную ситуацию с отсоединением узла ?
от сети А.
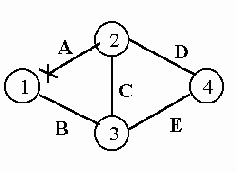
Рис. 4.2.1. Изменение состояния RIP-системы
Мы предполагали, что узел ?
не отправлял дейтаграмм через узел ?
(и, следовательно, изменение таблицы маршрутов в узле ?
не повлияло на таблицу узла ?
). Предположим теперь, что ?
отправлял дейтаграммы в сеть А через ?
, то есть таблица в узле ?
имела вид:
A=2a
?
B=1a
?
C=1a
?
D=2a
?
Е=1a
?
После отсоединения ?
от сети А узел ?
получает от ?
вектор (A=16,B=1,C=16,D=16,E=2). Проанализировав этот вектор, ?
делает вывод, что все указанные в нем расстояния больше значений, содержащихся в его маршрутной таблице, на основании чего этот вектор узлом ?
игнорируется.
В свою очередь узел ?
рассылает в сети В, С, Е вектор (A=2,B=1,C=1,D=2,E=1). Узел ?
получает этот вектор, увеличивает расстояния на 1: (А=3,В=2,С=2,D=3,E=2) и замечает, что расстояния А=3, С=2 и D=3 меньше бесконечности, следовательно, соответствующие записи таблицы маршрутов в узле ?
модифицируются и она принимает вид:
A=3a
?
B=1a
?
C=2a
?
D=3a
?
Е=2a
?
Очевидно, после этого содержимое таблиц узлов ?
и ?
стабилизируется.
Рассмотрим теперь записи о достижении сети А в таблицах маршрутизаторов ?
и ?
.
В узле ?
: A=3a
?
В узле ?
: A=2a
?
Таким образом, возникло зацикливание: данные, адресованные в сеть А, будут пересылаться между узлами ?
и ?
до тех пор, пока не истечет время жизни дейтаграмм и они не будут уничтожены.
Для того, чтобы избежать зацикливания, в алгоритм рассылки векторов расстояний вносятся следующие дополнения.
1. Если дейтаграммы, адресованные в сеть Х, посылаются через маршрутизатор G, находящийся в сети N, то в векторе расстояний, рассылаемом в сети N, расстояние до сети Х не указывается.
В нашем примере узел ?
будет рассылать в сети В вектор (B=1,C=1,D=2,E=1). Элемент А=2 не будет включен в этот вектор, потому что дейтаграммы в сеть А отправляются узлом ?
через узел ?
, а узел ?
находится в сети В. При рассылке узлом ?
вектора расстояний в другие сети элемент A=1 будет указан (но не будут указаны какие-то другие элементы).
2. Если маршрутизатор G объявляет новое расстояние до сети Х, то это расстояние вносится в таблицы маршрутов узлов, отправляющих дейтаграммы в сеть X через G, независимо от того, больше оно или меньше уже внесенного в таблицы расстояния.
В нашем примере это означает, что если в маршрутной таблице узла ?
записано А=1a
?
и ?
получает от ?
вектор с элементом А=16, то несмотря на то, что 1 меньше бесконечности, узел ?
модифицирует запись в таблице: А=16a
?
.
Очевидно, что при выполнении вышеуказанных условий зацикливания, рассмотренного в примере, не образуется и строятся корректные маршруты. Однако таким образом устраняются далеко не все случаи зацикливания.
Существует модификация дополнения 1, позволяющая ликвидировать более сложные особые ситуации, в том числе, некоторые случаи счета до бесконечности (см. также следующий пункт):
1А. Если дейтаграммы, адресованные в сеть Х, посылаются через маршрутизатор G, находящийся в сети N, то в векторе расстояний, рассылаемом в сети N, расстояние до сети Х полагается равным бесконечности.
Тем не менее и в этом случае особые ситуации все еще остаются.
Задача внешеней маршрутизации
В предыдущих главах мы рассмотрели протоколы маршрутизации, работающие внутри автономных систем. Задача следующего уровня– построение маршрутов между сетями, принадлежащими разным автономным системам.
Рассматриваемый на этом уровне, Интернет представляет собой множество автономных систем, произвольным образом соединенных между собой (рис. 7.1.1). Внутреннее строение автономных систем скрыто, известны только адреса IP-сетей, составляющих АС.

Рис. 7.1.1. Автономные системы
Автономные системы соединяются с помощью пограничных маршрутизаторов. Связи между маршрутизаторами могут иметь разную физическую природу: например, это может быть сеть Ethernet, к которой подключено сразу несколько пограничных маршрутизаторов разных автономных систем, выделенный канал типа "точка-точка" между двумя маршрутизаторами и т.п. Часто сама связующая сеть не принадлежит ни к одной автономной системе, в таком случае она называется демилитаризованной зоной (DMZ).
В зависимости от своего расположения в общей структуре Интернет автономная система может быть тупиковой (stub) – имеющей связь только с одной АС (АС7 на рис. 7.1.1), – или многопортовой (multihomed), т.е. имеющей связи с несколькими АС. Если административная политика автономной системы позволяет передавать через свои сети транзитный трафик других АС, то такую автономную систему можно назвать транзитной (transit).
Пограничный маршрутизатор сообщает связанным с ним другим пограничным маршрутизаторам, какие сети каких автономных систем достижимы через него. Обмен подобной информацией позволяет пограничным маршрутизаторам занести в таблицу маршрутов записи о сетях, находящихся в других АС. При необходимости эта информация потом распространяется внутри своей автономной системы с помощью протоколов внутренней маршрутизации (см., например, внешние маршруты в OSPF) с тем, чтобы обеспечить внешнюю коннективность своей АС.
Задачей этого пункта является обсуждение протокола обмена маршрутной информацией между пограничными маршрутизаторами.
Принципиальным отличием внешней маршрутизации от внутренней является наличие маршрутной политики, то есть при расчете маршрута рассматривается не столько метрика, сколько политические и экономические соображения. Это обстоятельство не позволяет адаптировать под задачу внешней маршрутизации готовые протоколы внутренней маршрутизации, просто применив их к графу автономных систем, как раньше они применялись к графу сетей. По той же причине существующие подходы – дистанционно-векторный и состояния связей – непригодны для решения поставленной задачи.
Например, рассмотрим систему маршрутизаторов, аналогичную графу автономных систем, изображенному на рис. 7.1.1. Алгоритм SPF гарантирует, что если узел (1) вычислил маршрут в узел (6) как (1)-(3)-(5)-(6), то узел (3) также будет использовать маршрут (3)-(5)-(6). Это происходит потому, что все узлы одинаково интерпретируют метрики связей и используют одни и те же математические процедуры для вычисления маршрутов. Однако если применять протокол состояния связей на уровне автономных систем может произойти следующее: АС1 установила, что оптимальный маршрут по соображениям пропускной способности сетей в АС6 выглядит 1-3-5-6. Но АС3 считает, что выгодней добираться в АС6 по маршруту 3-1-2-4-6, так как АС5 дорого берет за передачу транзитного трафика. В итоге, из-за того, что у каждой АС свое понятие метрики, то есть качества маршрута, происходит зацикливание.
Казалось бы, дистанционно-векторный подход мог бы решить проблему: АС3, не желающая использовать АС5 для транзита в АС6, просто не прислала бы в АС1 элемент вектора расстояний для АС6, следовательно первая система никогда не узнала бы о маршруте 1-3-5-6. Но с другой стороны при использовании дистанционно-векторного подхода получателю вектора расстояний неизвестно описание маршрута на всей его протяженности. Рассмотрим другую политическую ситуацию на примере того же рис. 7.1.1: АС1 получает от АС3 вектор АС6=2 и направляет свой трафик в АС6 через АС3, не подозревая, что на этом маршруте располагается АС5, которая находится с АС1 в состоянии войны и, естественно, не пропускает транзитный трафик от и для АС1. В результате АС1, установив внешне безобидный маршрут в АС6, осталась без связи с этой автономной системой. Если бы АС1 получила полное описание маршрута, то она несомненно бы выбрала альтернативный вариант 1-2-4-6, однако в дистанционно-векторных протоколах такая информация не передается.
Для решения задачи внешней маршрутизации был разработан протокол BGP (Border Gateway Protocol). Используемая в настоящий момент версия этого протокола имеет номер 4, соответствующий стандарт – RFC-1771, 1772.
Общая схема работы BGP такова. BGP-маршрутизаторы соседних АС, решившие обмениваться маршрутной информацией, устанавливают между собой соединения по протоколу BGP и становятся BGP-соседями (BGP-peers).
Далее BGP использует подход под названием path vector, являющийся развитием дистанционно-векторного подхода. BGP-соседи рассылают (анонсируют, advertise) друг другу векторы путей (path vectors). Вектор путей, в отличие от вектора расстояний, содержит не просто адрес сети и расстояние до нее, а адрес сети и список атрибутов (path attributes), описывающих различные характеристики маршрута от маршрутизатора-отправителя в указанную сеть. В дальнейшем для краткости мы будем называть набор данных, состоящих из адреса сети и атрибутов пути до этой сети, маршрутом в данную сеть.
Данных, содержащихся в атрибутах пути, должно быть достаточно, чтобы маршрутизатор-получатель, проанализировав их с точки зрения политики своей АС, мог принять решение о приемлемости или неприемлемости полученного маршрута.
Например, наиболее важным атрибутом маршрута является AS_PATH – список номеров автономных систем, через которые должна пройти дейтаграмма на пути в указанную сеть. Атрибут AS_PATH можно использовать для:
обнаружения циклов – если номер одной и той же АС встречается в AS_PATH дважды;
вычисления метрики маршрута – метрикой в данном случае является число АС, которые нужно пересечь;
применения маршрутной политики – если AS_PATH содержит номера политически неприемлемых АС, то данный маршрут исключается из рассмотрения.
Анонсируя какой-нибудь маршрут, BGP-маршрутизатор добавляет в AS_PATH номер своей автономной системы.
Другие атрибуты будут рассмотрены в п. .
Заголовок LSA
Все объявления о состоянии связей (LSA) состоят из заголовка и тела и пересылаются в сообщениях OSPF типа 4 (см. ), а заголовки отдельно также пересылаются в сообщениях типа 2 и 5 (см. пп. и соответственно). Заголовок LSA имеет одинаковый формат для всех типов LSA.
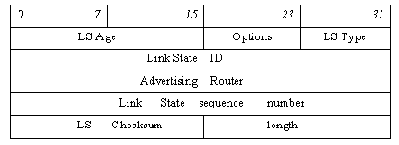
Значения полей:
LS Age (2 октета) - возраст связи (связей), содержащихся в данном LSA (см. выше п. 5.2.3).
Options (1 октет) - содержимое октета аналогично такому же октету в сообщении Hello.
LS Type (1 октет) - тип LSA (см. предыдущий пункт);
Link State ID (4 октета) - идентификатор связи (связей), объявляемых в данном LSA, интерпретация этого поля зависит от типа LSA:
Тип LSA
Link State ID
1
то же, что и "Advertising Router"
2
IP-адрес интерфейса выделенного маршрутизатора, подключенного к данной сети множественного доступа
3
IP-адрес сети, находящейся за пределами области
4
идентификатор ASBR
5
IP-адрес сети, находящейся за пределами системы
Advertising Router (4 октета) - идентификатор маршрутизатора, ответственного за объявление и поддержку связи (связей), содержащихся в данном LSA.
Link State sequence number (4 октета) - порядковый номер (версия) состояния связи (связей), содержащихся в данном LSA. Порядковые номера изменяются от 1-N до N-1, где N=231=2147483648, номер -N не используется. При достижении записью номера N-1 маршрутизатор, ответственный за эту запись, принудительно удаляет ее из базы данных путем присвоения ей максимального возраста (см. п. 5.2.3), после чего заново объявляет ее с начальным номером 1-N.
LS Checksum (2 октета) - контрольная сумма, вычисляется таким же методом, что и контрольная сумма IP-заголовка; защищает как заголовок, так и тело LSA.
length (2 октета) - длина LSA в октетах, включая 20 октетов заголовка LSA.
Заголовок TCP-сегмента
TCP-сегмент состоит из заголовка и данных.
Заголовок сегмента состоит из 32-разрядных слов и имеет переменную длину, зависящую от размера поля Options, но всегда кратную 32 битам. За заголовком непосредственно следуют данные- часть потока данных пользователя, передаваемая в данном сегменте.
Формат заголовка:

Значения полей заголовка следующие.
Source Port (16 бит), Destination Port (16 бит) - номера портов процесса-отправителя и процесса-получателя соответственно.
Sequence Number (SN) (32 бита) - порядковый номер первого октета в поле данных сегмента среди всех октетов потока данных для текущего соединения, то есть если в сегменте пересылаются октеты с 2001-го по 3000-й, то SN=2001. Если в заголовке сегмента установлен бит SYN (фаза установления соединения), то в поле SN записывается начальный номер (ISN), например, 0. Номер первого октета данных, посылаемых после завершения фазы установления соединения, равен ISN+1. Acknowledgment Number (ACK) (32 бита) - если установлен бит ACK, то это поле содержит порядковый номер октета, который отправитель данного сегмента желает получить. Это означает, что все предыдущие октеты (с номерами от ISN+1 до ACK-1 включительно) были успешно получены.
Data Offset (4 бита) - длина TCP-заголовка в 32-битных словах.
Reserved (6 бит) - зарезервировано; заполняется нулями.
Control Bits (6 бит) - управляющие биты; активным является положение “бит установлен”.
URG - поле срочного указателя (Urgent Pointer) задействовано;
ACK - поле номера подтверждения (Acknowledgment Number) задействовано;
PSH - осуществить “проталкивание” - если модуль TCP получает сегмент с установленным флагом PSH, то он немедленно передает все данные из буфера приема процессу-получателю для обработки, даже если буфер не был заполнен;
RST - перезагрузка текущего соединения;
SYN - запрос на установление соединения;
FIN - нет больше данных для передачи.
Window (16 бит) - размер окна в октетах (см. выше ).
Checksum (16 бит) - контрольная сумма, представляет собой 16 бит, дополняющие биты в сумме всех 16-битовых слов сегмента (само поле контрольной суммы перед вычислением обнуляется). Контрольная сумма, кроме заголовка сегмента и поля данных, учитывает 96 бит псевдозаголовка, который для внутреннего употребления ставится перед TCP-заголовком. Этот псевдозаголовок содержит IP-адрес отправителя (4 октета), IP-адрес получателя (4 октета), нулевой октет, 8-битное поле "Протокол", аналогичное полю в IP-заголовке, и 16 бит длины TCP сегмента, измеренной в октетах. Такой подход обеспечивает защиту протокола TCP от ошибшихся в маршруте сегментов. Информация для псевдозаголовка передается через интерфейс "Протокол TCP/межсетевой уровень" в качестве аргументов или результатов запросов от протокола TCP к протоколу IP.
Urgent Pointer (16 бит) - используется для указания длины срочных данных, которые размещаются в начале поля данных сегмента. Указывает смещение октета, следующего за срочными данными, относительно первого октета в сегменте. Например, в сегменте передаются октеты с 2001-го по 3000-й, при этом первые 100 октетов являются срочными данными, тогда Urgent Pointer = 100. Протокол TCP не определяет, как именно должны обрабатываться срочные денные, но предполагает, что прикладной процесс будет предпринимать усилия для их быстрой обработки. Поле Urgent Pointer задействовано, если установлен флаг URG.
Options - поле переменной длины; может отсутствовать или содержать одну опцию или список опций, реализующих дополнительные услуги протокола TCP. Опция состоит из октета "Тип опции", за которым могут следовать октет "Длина опции в октетах" и октеты с данными для опции.
Стандарт протокола TCP определяет три опции (типы 0,1,2).
Опции типов 0 и 1 ("Конец списка опций" и "Нет операции" соответственно) состоят из одного октета, содержащего значение типа опции. При обнаружении в списке опции "Конец списка опций" разбор опций прекращается, даже если длина заголовка сегмента (Data Offset) еще не исчерпана. Опция "Нет операции" может использоваться для выравнивания между опциями по границе 32 бит.
Опция типа 2 "Максимальный размер сегмента" состоит из 4 октетов: одного октета типа опции (значение равно 2), одного октета длины (значение равно 4) и двух октетов, содержащих максимальный размер сегмента, который способен получать TCP-модуль, отправивший сегмент с данной опцией. Опцию следует использовать только в SYN-сегментах на этапе установки соединения.
Padding - выравнивание заголовка по границе 32-битного слова, если список опций занимает нецелое число 32-битных слов. Поле Padding заполняется нулями.
Запись адресов в бесклассовой модели
Для удобства записи IP-адрес в модели CIDR часто представляется в виде a.b.c.d / n, где a.b.c.d— IP адрес, n — количество бит в сетевой части.
Пример: 137.158.128.0/17.
Маска сети для этого адреса: 17 единиц (сетевая часть), за ними 15 нулей (хостовая часть), что в октетном представлении равно
11111111.11111111.10000000.00000000 = 255.255.128.0.
Представив IP-адрес в двоичном виде и побитно умножив его на маску сети, мы получим номер сети (все нули в хостовой части). Номер хоста в этой сети мы можем получить, побитно умножив IP-адрес на инвертированную маску сети.
Пример: IP = 205.37.193.134/26 или, что то же,
IP = 205.37.193.134 netmask = 255.255.255.192.
Распишем в двоичном виде:
IP = 11001101 00100101 11000111 10000110 маска = 11111111 11111111 11111111 11000000
Умножив побитно, получаем номер сети (в хостовой части - нули):
network = 11001101 00100101 11000111 10000000
или, в октетном представлении, 205.37.193.128/26, или, что то же, 205.37.193.128 netmask 255.255.255.192.
Хостовая часть рассматриваемого IP адреса равна 000110, или 6. Таким образом, 205.37.193.134/26 адресует хост номер 6 в сети 205.37.193.128/26. В классовой модели адрес 205.37.193.134 определял бы хост 134 в сети класса С 205.37.193.0, однако указание маски сети (или количества бит в сетевой части) однозначно определяет принадлежность адреса к бесклассовой модели.
Упражнение. Покажите, что адрес 132.90.132.5 netmask 255.255.240.0 определяет хост 4.5 в сети 132.90.128.0/20 (в классовой модели это был бы хост 132.5 в сети класса В 132.90.0.0). Найдите адрес broadcast для этой сети.
Очевидно, что сети классов А, В, С в бесклассовой модели представляются при помощи масок, соответственно, 255.0.0.0 (или /8), 255.255.0.0 (или /16) и 255.255.255.0 (или /24).
Защита хоста
Мероприятия по защите хоста проводятся для предотвращения атак, цель которых — перехват данных, отказ в обслуживании, или проникновение злоумышленника в операционную систему.
Запретить обработку ICMP Echo-запросов, направленных на широковещательный адрес. Запретить обработку ICMP-сообщений Redirect, Address Mask Reply, Router Advertisement, Source Quench. Если хосты локальной сети конфигурируются динамически сервером DHCP, использовать на DHCP-сервере таблицу соответствия MAC- и IP-адресов и выдавать хостам заранее определенные IP-адреса. Отключить все ненужные сервисы TCP и UDP (читай: отключить все сервисы, кроме явно необходимых). Под отключением сервиса мы понимаем перевод соответствующего порта из состояния LISTEN в CLOSED. Если входящие соединения обслуживаются супердемоном inetd, то использовать оболочки или заменить inetd на супердемон типа или , позволяющий устанавливать максимальное число одновременных соединений, список разрешенных адресов клиентов, выполнять проверку легальности адреса через DNS и регистрировать соединения в лог-файле. Использовать программу типа , позволяющую отследить попытки скрытного сканирования (например, полуоткрытыми соединениями). Использовать статическую ARP-таблицу узлов локальной сети. Применять средства безопасности используемых на хосте прикладных сервисов. Использовать последние версии и обновления программного обеспечения, следить за бюллетенями по безопасности, выпускаемыми производителем.
Защита маршрутизатора
Мероприятия по защите маршрутизатора проводятся с целью предотвращения атак, направленных на нарушение схему маршрутизации датаграмм или на захват маршрутизатора злоумышленником.
Использовать аутентификацию сообщений протоколов маршрутизации с помощью алгоритма MD5. Осуществлять фильтрацию маршрутов, объявляемых сетями-клиентами, провайдером или другими автономными системами. Фильтрация выполняется в соответствии с маршрутной политикой организации; маршруты, не соответствующие политике, игнорируются. Использовать на маршрутизаторе, а также на коммутаторах статическую ARP-таблицу узлов сети организации. Отключить на маршрутизаторе все ненужные сервисы (особенно так называемые «диагностические» или «малые» сервисы TCP: echo, chargen, daytime, discard, и UDP: echo, chargen, discard). Ограничить доступ к маршрутизатору консолью или выделенной рабочей станцией администратора, использовать парольную защиту; не использовать telnet для доступа к маршрутизатору в сети, которая может быть прослушана. Использовать последние версии и обновления программного обеспечения, следить за бюллетенями по безопасности, выпускаемыми производителем.
